从扣减库存的简单案例开始 首先创建一个项目,pom对应代码为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 <?xml version="1.0" encoding="UTF-8"?> <project xmlns ="http://maven.apache.org/POM/4.0.0" xmlns:xsi ="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation ="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd" > <modelVersion > 4.0.0</modelVersion > <parent > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-parent</artifactId > <version > 2.7.3</version > <relativePath /> </parent > <groupId > cn.springcoder</groupId > <artifactId > demo-distributed-lock</artifactId > <version > 0.0.1-SNAPSHOT</version > <name > demo-distributed-lock</name > <description > demo-distributed-lock</description > <properties > <java.version > 1.8</java.version > </properties > <dependencies > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-web</artifactId > </dependency > <dependency > <groupId > org.projectlombok</groupId > <artifactId > lombok</artifactId > <optional > true</optional > </dependency > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-test</artifactId > <scope > test</scope > </dependency > </dependencies > <build > <plugins > <plugin > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-maven-plugin</artifactId > <configuration > <excludes > <exclude > <groupId > org.projectlombok</groupId > <artifactId > lombok</artifactId > </exclude > </excludes > </configuration > </plugin > </plugins > </build > </project >
创建一个Service和Controller,代码示例如下:
StockController 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 package cn.springcoder.demo.distributed.lock.controller;import cn.springcoder.demo.distributed.lock.service.StockService;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.RestController;@RestController @RequestMapping("stock") public class StockController @Autowired private StockService stockService; @RequestMapping("deduction") public Boolean deduction () return stockService.deduction(); } }
StockService 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 package cn.springcoder.demo.distributed.lock.service;import lombok.extern.slf4j.Slf4j;import org.springframework.stereotype.Service;@Service @Slf4j public class StockService private Long count = 50000L ; public Boolean deduction () if (count <= 0 ) { log.warn("库存不够啦!!!={}" , count); return false ; } log.info("库存余量:{}" , --count); return true ; } }
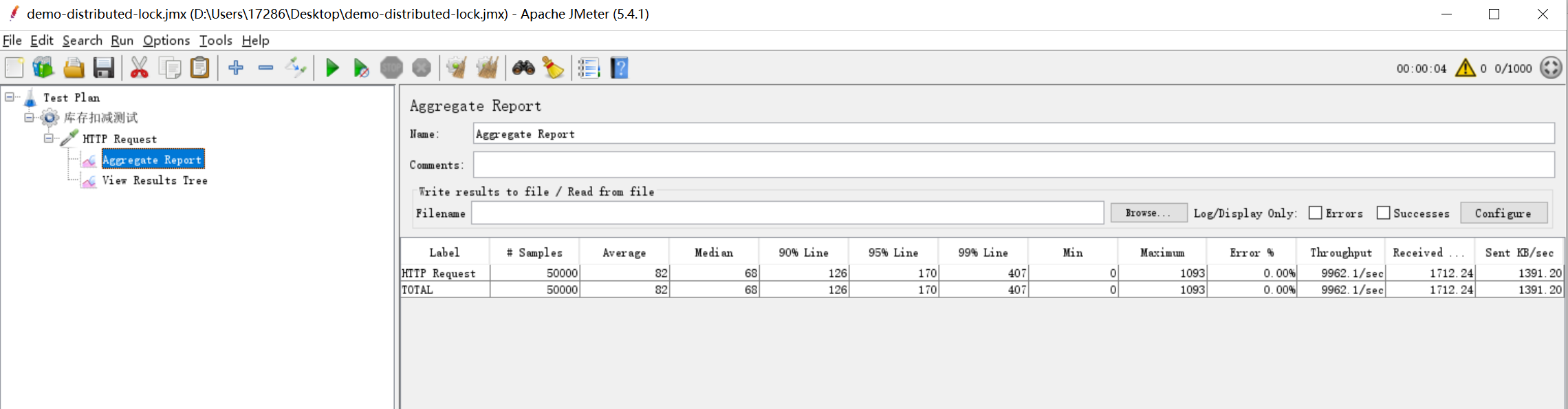
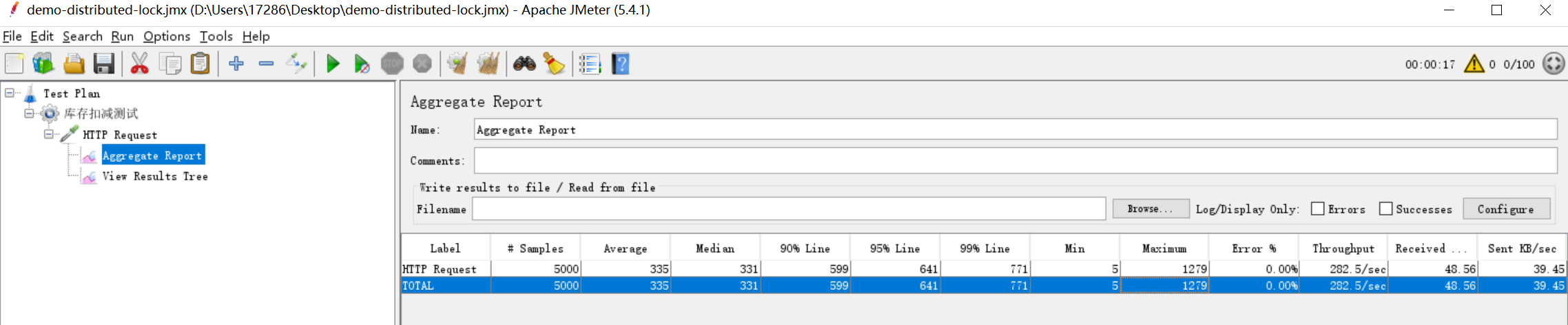
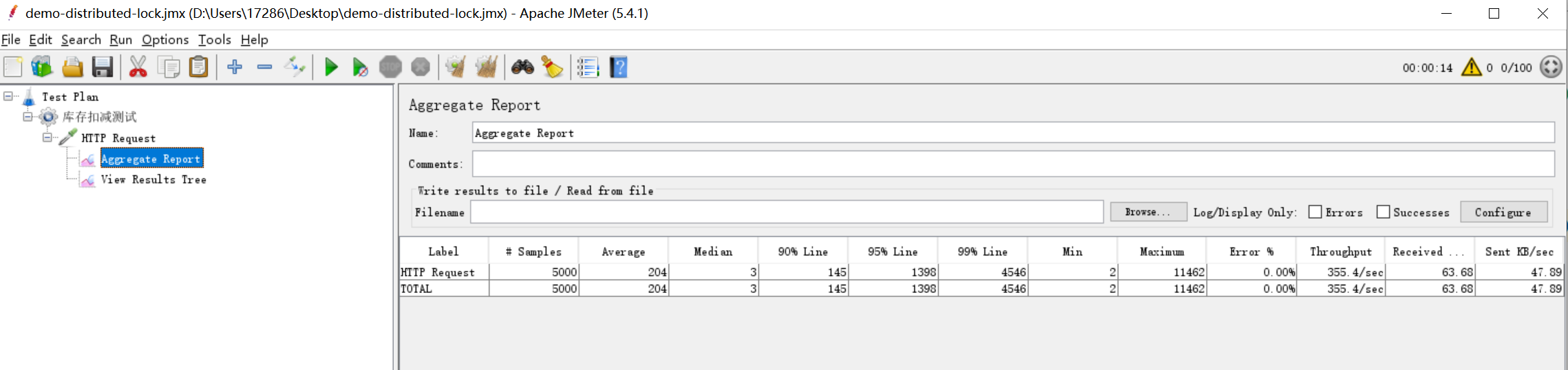
这样,一个简单的测试工程就创建完成了,这里的并发测试工具使用JMeter,工具的使用这里不做介绍,我们添加一个http请求进行测试,并添加一个汇总报告Aggregate Report用于查看请求结果。1000个线程(模拟1000个用户),每个线程循环请求50次,总共请求50000次,其报告如图所示:
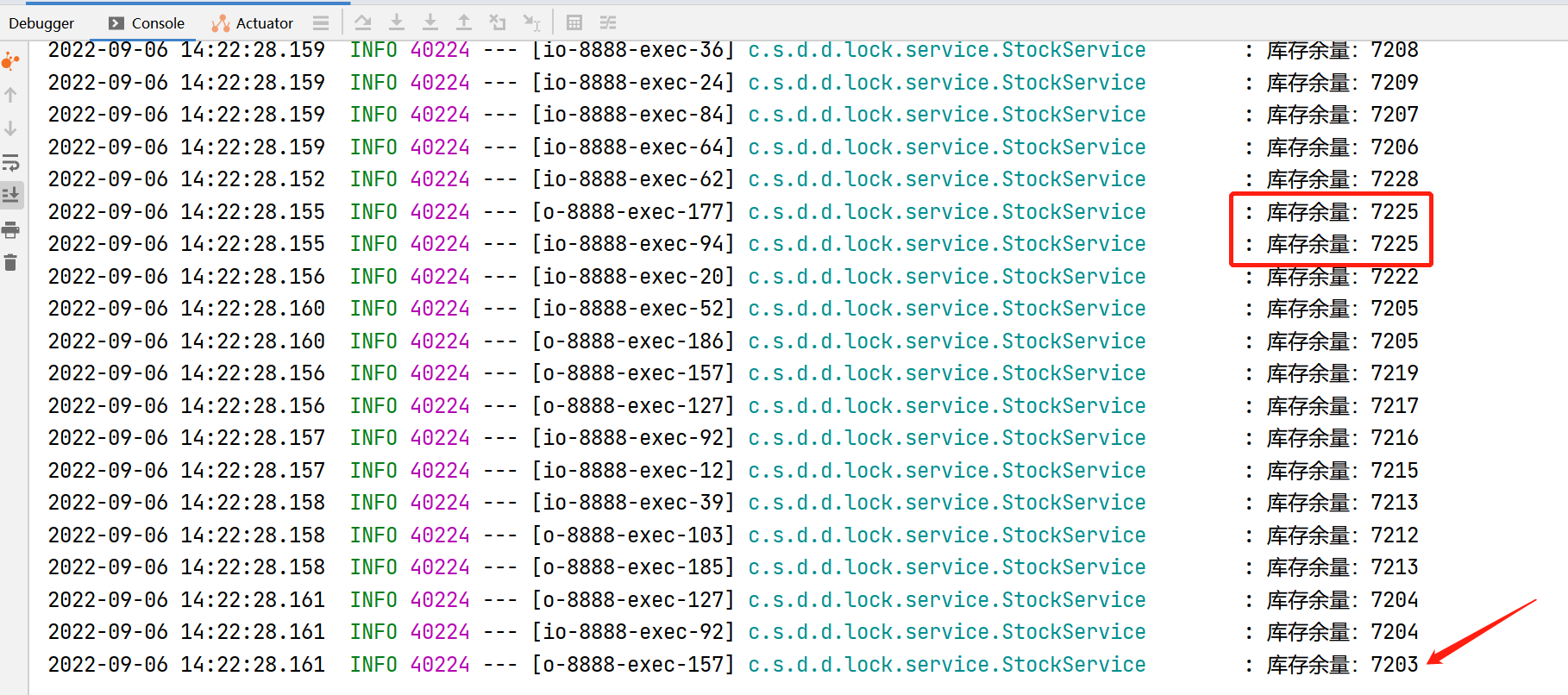
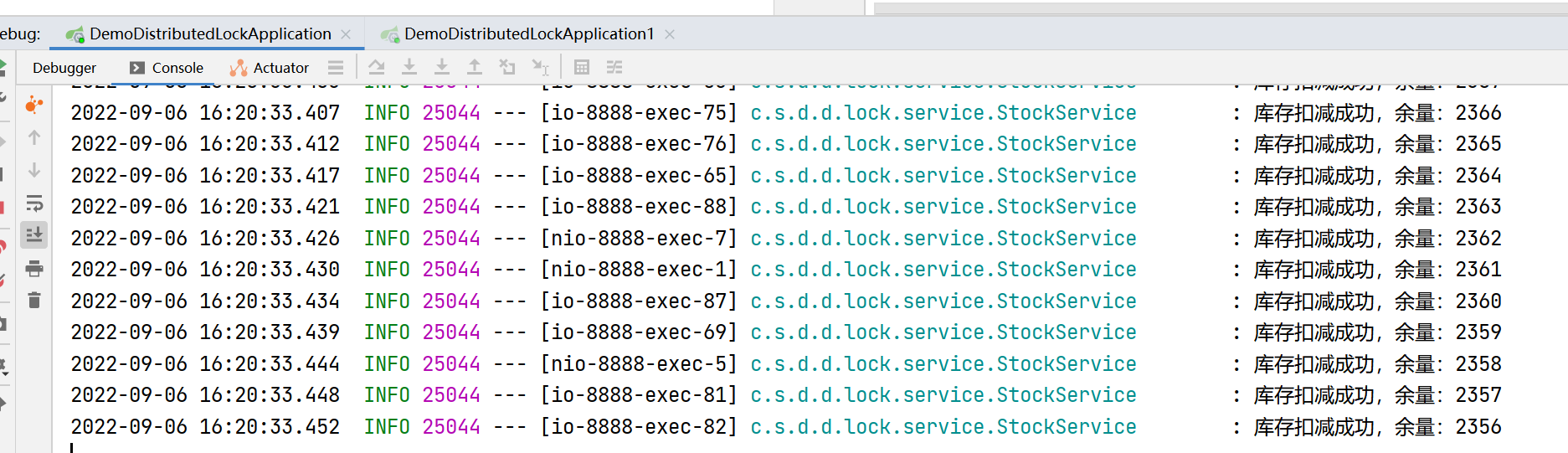
可以看到,并发量相当的大,达到了9962.14/s的并发,50000个请求,在4秒左右就执行完毕。但是当我们看控制台打印的日志,就不容乐观了:
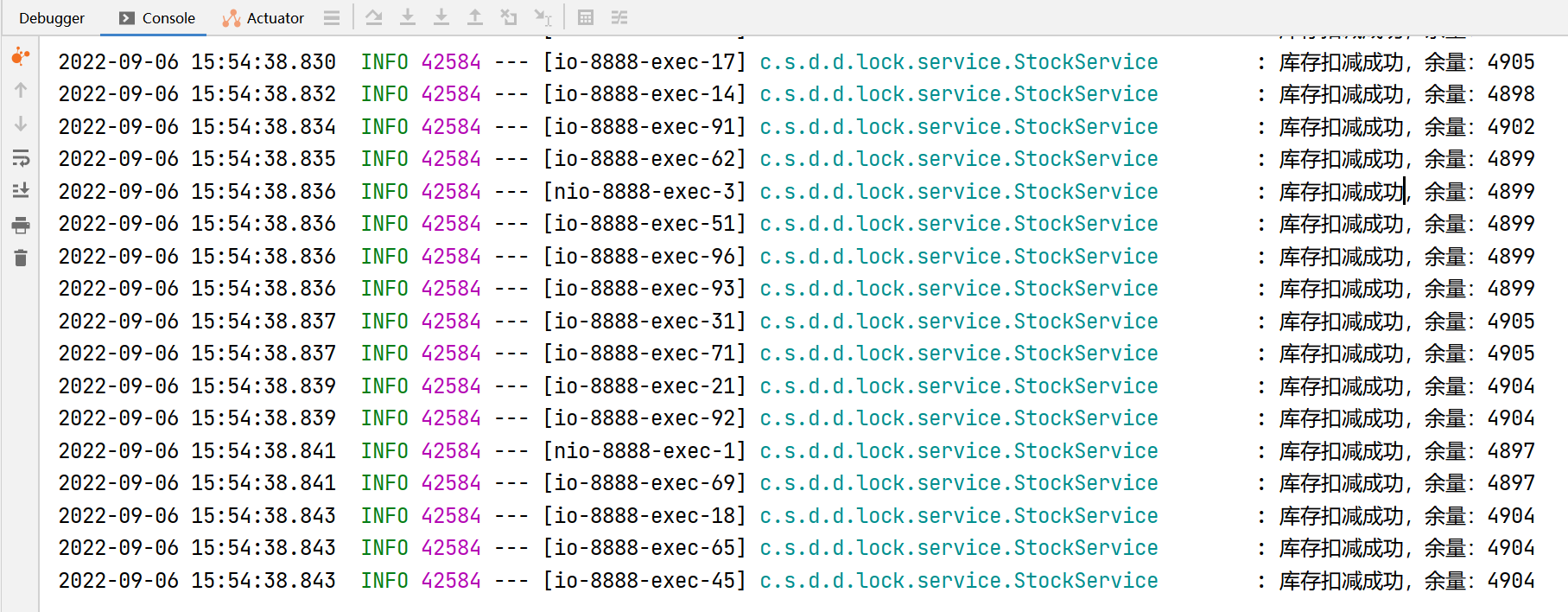
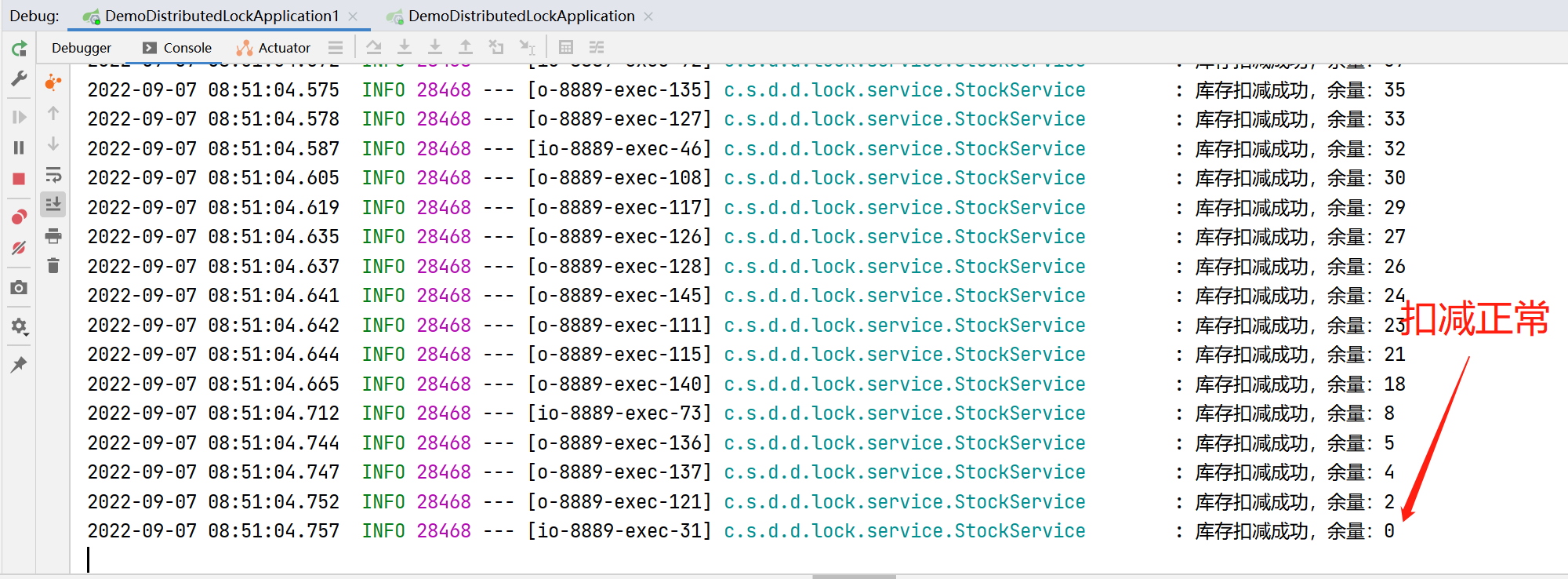
从日志中可以看到,最后的输出中,库存余量还有7203,正常逻辑,应该是50000次请求结束,库存为0才符合逻辑,并且可以看到,其中有的库存输出是重复的,这就是并发导致的问题了。这会导致超卖,比如库存只有50000,已经有50000个人购买成功了,但是库存中显示还有七千多,必然导致有的用户购买成功后拿不到货,因为库存中并没有那么多。
基于JVM的本地锁解决超卖 基于上述问题,我们尝试用JVM自带的锁synchronized去解决并发导致的超卖问题。只需简单改动,在Service的方法上加上关键字synchronized即可,修改后的代码为:
1 public synchronized Boolean deduction ()
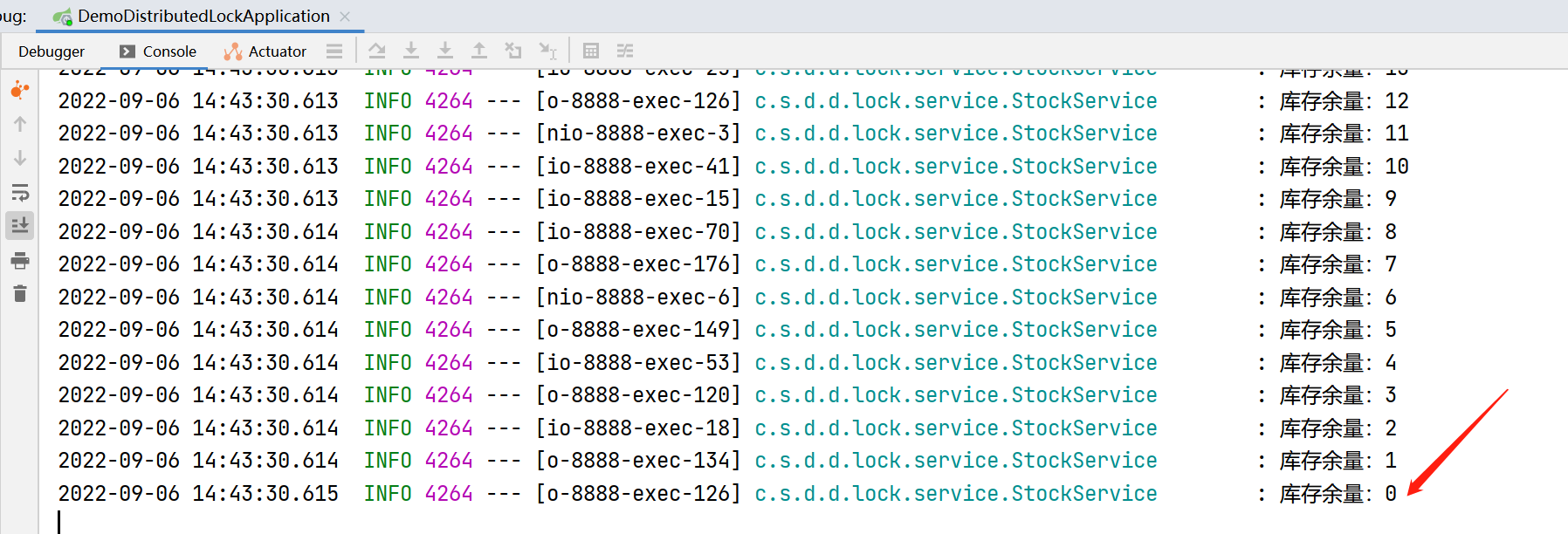
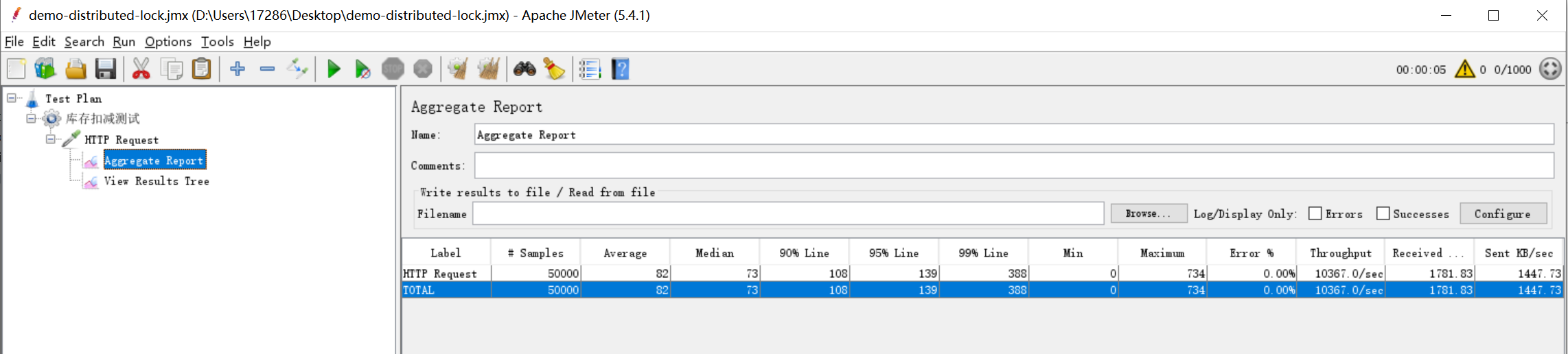
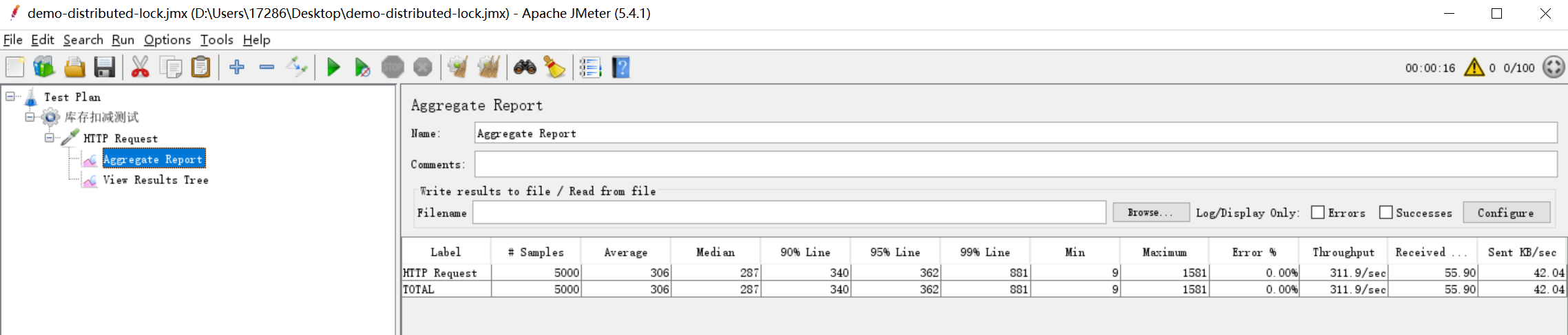
修改代码后,重启项目,重新执行测试,可以看到,控制台中最终的库存量为0了,符合预期,并且吞吐量达到了10366.99/s。
JVM解决MYSQL的超卖 以上的测试,数据都是在程序中的,这在现实中是不大实际的,现实中的数据通常都是存在数据库中的,我们在数据库(distributed_lock)中创建一张表进行测试,数据库建表脚本如下:
1 2 3 4 5 6 7 8 9 CREATE TABLE db_stock ( id BIGINT AUTO_INCREMENT COMMENT '主键' PRIMARY KEY, product_code VARCHAR(20) NULL COMMENT '商品编码', warehouse VARCHAR(20) NULL COMMENT '仓库', count INT NULL COMMENT '库存量' ); INSERT INTO distributed_lock.db_stock (id, product_code, warehouse, count) VALUES (1, '1001', '北京仓', 5000);
引入mybatis-plus操作数据,需要添加的依赖如下:
1 2 3 4 5 6 7 8 9 <dependency > <groupId > com.baomidou</groupId > <artifactId > mybatis-plus-boot-starter</artifactId > <version > 3.5.2</version > </dependency > <dependency > <groupId > mysql</groupId > <artifactId > mysql-connector-java</artifactId > </dependency >
如此,我们的业务逻辑就变成了如下流程:
发起请求
从数据库查询数据
判断库存是否大于0(这里测试默认每个请求只购买数量1的货物)
如果不大于零,返回失败
如果大于0,库存减一,并回写数据库,返回成功
如此,我们基于上述代码进行改造,首先需要添加一个实体类,用于数据交互:
Stock实体 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 package cn.springcoder.demo.distributed.lock.entity;import com.baomidou.mybatisplus.annotation.TableName;import lombok.Data;@Data @TableName("db_stock") public class Stock private Long id; private String productCode; private String warehouse; private Integer count; }
创建数据库操作的mapper
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 package cn.springcoder.demo.distributed.lock.mapper;import cn.springcoder.demo.distributed.lock.entity.Stock;import com.baomidou.mybatisplus.core.mapper.BaseMapper;import org.apache.ibatis.annotations.Mapper;@Mapper public interface StockMapper extends BaseMapper <Stock > }
在启动类上添加注解,扫描mapper
1 @MapperScan("cn.springcoder.demo.distributed.lock.mapper")
项目配置文件如下:
1 2 3 4 5 6 7 8 9 10 server: port: 8888 servlet: context-path: /demoLock spring: datasource: username: root password: root driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://127.0.0.1:3306/distributed_lock
Service代码改造如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 package cn.springcoder.demo.distributed.lock.service;import cn.springcoder.demo.distributed.lock.entity.Stock;import cn.springcoder.demo.distributed.lock.mapper.StockMapper;import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;import lombok.extern.slf4j.Slf4j;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.stereotype.Service;@Service @Slf4j public class StockService @Autowired private StockMapper stockMapper; public synchronized Boolean deduction () Stock stock = stockMapper.selectOne(new QueryWrapper<Stock>().eq("product_code" , "1001" )); if (stock != null && stock.getCount() > 0 ) { stock.setCount(stock.getCount() - 1 ); stockMapper.updateById(stock); log.info("库存扣减成功,余量:{}" , stock.getCount()); return true ; } log.info("库存扣减失败,库存信息:{}" , stock); return false ; } }
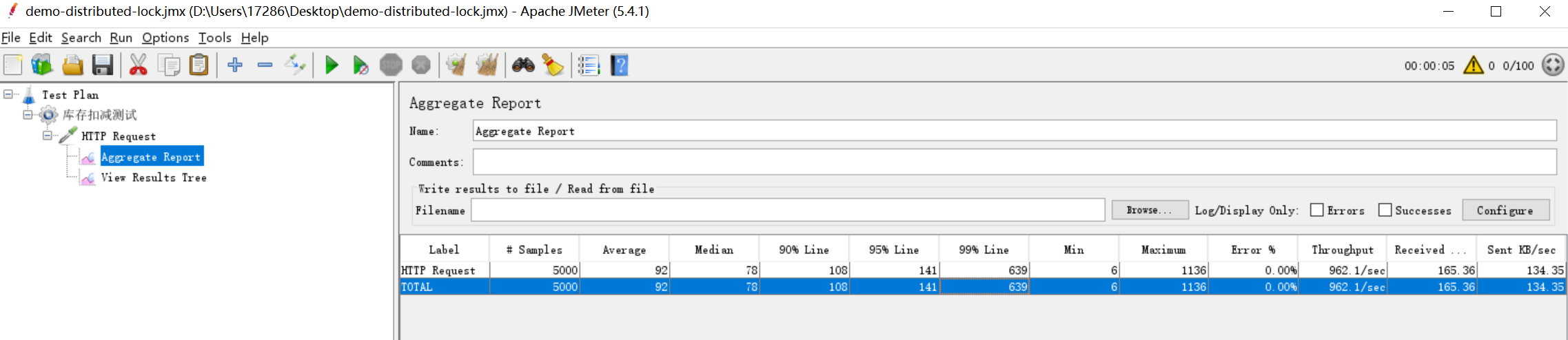
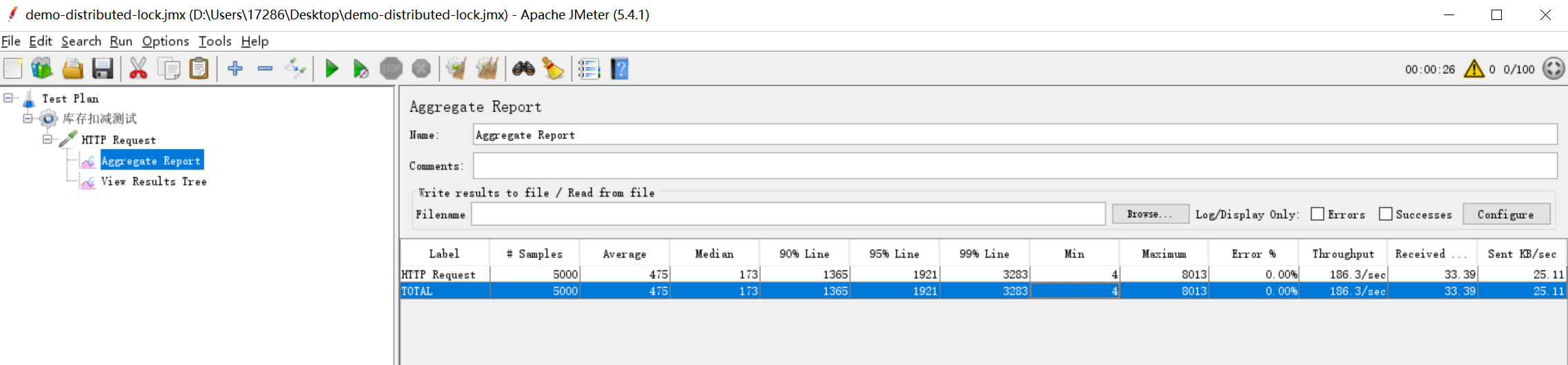
通过日志,我们可以看到库存扣减符合预期,没有出现超卖的问题,但是吞吐量一下就降下来了,只有282.52/s(为了节省时间,测试线程由1000减少为100)。
在JVM中除了使用关键字synchronized进行加锁,还可以使用JDK自带的工具类ReentrantLock进行加锁,测试效率与使用关键字synchronized相差无几,下面是使用ReentrantLock加锁的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 package cn.springcoder.demo.distributed.lock.service;import cn.springcoder.demo.distributed.lock.entity.Stock;import cn.springcoder.demo.distributed.lock.mapper.StockMapper;import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;import lombok.extern.slf4j.Slf4j;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.stereotype.Service;import java.util.concurrent.locks.Lock;import java.util.concurrent.locks.ReentrantLock;@Service @Slf4j public class StockService private Lock lock = new ReentrantLock(); @Autowired private StockMapper stockMapper; public Boolean deduction () lock.lock(); try { Stock stock = stockMapper.selectOne(new QueryWrapper<Stock>().eq("product_code" , "1001" )); if (stock != null && stock.getCount() > 0 ) { stock.setCount(stock.getCount() - 1 ); stockMapper.updateById(stock); log.info("库存扣减成功,余量:{}" , stock.getCount()); return true ; } log.info("库存扣减失败,库存信息:{}" , stock); } finally { lock.unlock(); } return false ; } }
JVM锁失效之多例模式 使用JVM锁解决并发问题是有条件的,不满足条件则锁不住:
必须是单例模式
单体部署,不能部署集群
不能添加事务
我们可以通过案例进行测试,首先测试多例模式看看JVM自带的锁是否能解决并发,我们将上述的Service代码添加如下注解:
1 2 3 4 5 import org.springframework.beans.factory.config.ConfigurableBeanFactory;import org.springframework.context.annotation.Scope;import org.springframework.context.annotation.ScopedProxyMode;@Scope(value = ConfigurableBeanFactory.SCOPE_PROTOTYPE, proxyMode = ScopedProxyMode.TARGET_CLASS)
通过测试可以发现,吞吐量达到了962.09/s,但是数据错误得离谱,查看数据库中的库存量,还有4904,相当于卖了5000份,但库存扣减还不到1000。
JVM锁失效之集群部署
在Windows环境中,官方的nginx做负载均衡,高并发测试时,会报很多nginx的错误,因此,这里搭建集群环境,我们使用nginx Unicorn,下载链接为:Index of /download/ (ecsds.eu)
环境搭建 通过上述链接下载nginx,解压文件夹,其中有个修改注册表的文件Tweak-Optimize tcpip parameters for nginx connections.reg,双击运行即可,这个文件是修改注册表信息,修改最大端口数、最大tcp连接数等信息。
然后将文件conf/nginx-win.conf重命名为nginx.conf,并将配置信息修改如下,其中具体信息可根据自己项目实际情况修改,这里我们做两个集群的配置:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 worker_processes 2 ;events { worker_connections 8192 ; } http { include mime.types; default_type application/octet-stream; sendfile off ; server_tokens off ; server_names_hash_bucket_size 128 ; map_hash_bucket_size 64 ; client_body_timeout 10 ; client_header_timeout 10 ; keepalive_timeout 30 ; send_timeout 10 ; keepalive_requests 10 ; upstream demoLock { server 127.0.0.1:8888 weight=1 max_fails=2 fail_timeout=10s ; server 127.0.0.1:8889 weight=1 max_fails=2 fail_timeout=10s ; least_conn; } server { listen 80 ; server_name localhost; location /demolock { root html; index index.html index.htm; proxy_pass http://demoLock; } } }
配置好后,双击nginx.exe启动nginx即可。
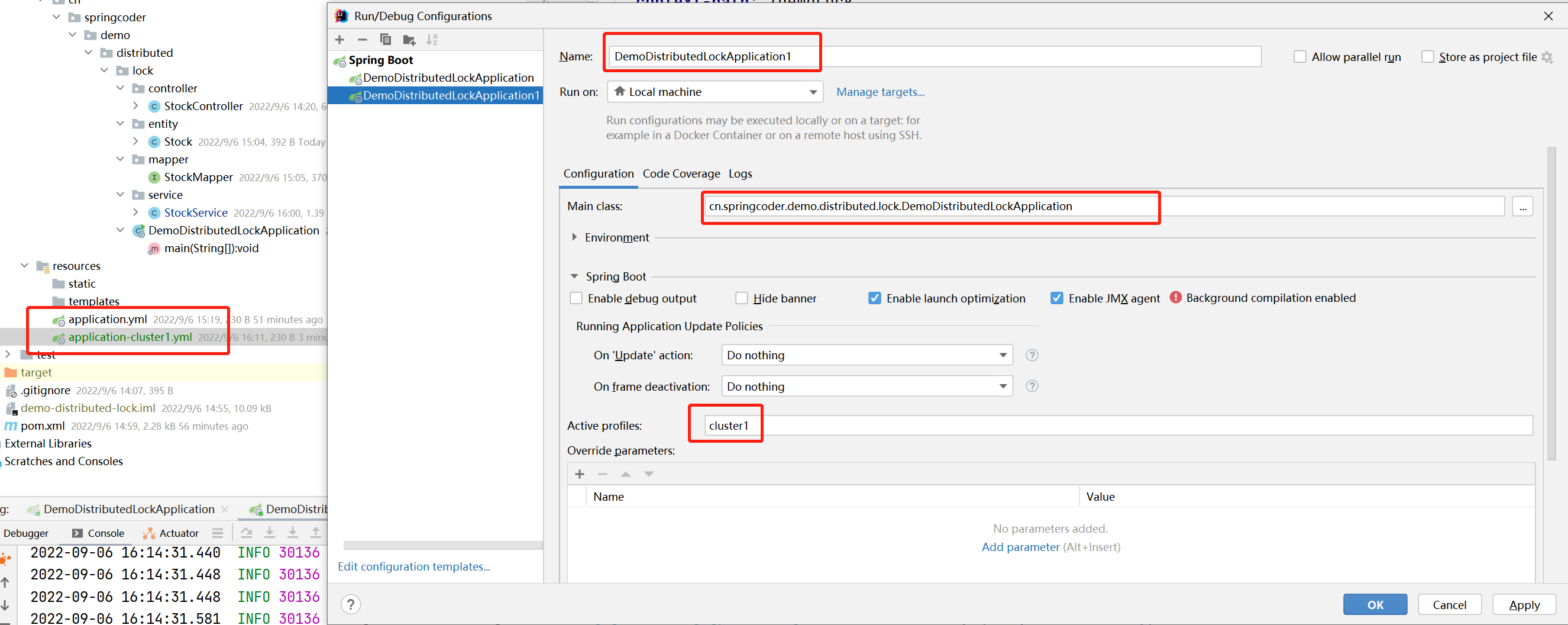
在项目中,我们复制一份配置文件,重命名为application-cluster1.yml,然后修改项目端口为8889。在idea中配置第二个启动程序,用于集群部署启动,如图:
然后我们在idea中启动两个项目,将JMeter请求改为80端口,让nginx做负载均衡,即可实现简单的集群搭建。
执行测试 我们将上述的多例模式还原为单例模式,不进行其他修改,然后进行并发测试。
通过日志可以发现,程序执行结束,但是库存最终并没有扣减到0,而是2356,查看数据库,也是2356,说明JVM锁不适用于集群部署,通过部署两个集群,可以发现相对于一个项目的并发(282.52/s)有所提高,达到525.65/s,但是没解决数据问题,并发再高也是无用。
JVM锁失效之事务 我们部署一个项目,在方法上添加注解@Transactional,然后执行测试,根据结果可发现,5000个请求测试结束后,数据库中的库存还有2484,这是由于spring事务的默认隔离级别是可重复读,如果将注解改为@Transactional(isolation = Isolation.READ_UNCOMMITTED),可读取未提交事务,再次进行测试,那么库存扣减符合预期,但是开发中也不会这么使用。
下面详细说明下可重复读的事务导致锁不住的根本原因。
首先我们在本地打开两个命令行窗口连接MySQL,模拟两个用户操作数据,首先用户1开启事务,查询库存,并更新库存,但是事务还未提交:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 mysql> begin; Query OK, 0 rows affected (0.00 sec) mysql> select * from db_stock where id = 1; +----+--------------+-----------+-------+ | id | product_code | warehouse | count | +----+--------------+-----------+-------+ | 1 | 1001 | 北京仓 | 5000 | +----+--------------+-----------+-------+ 1 row in set (0.00 sec) mysql> update db_stock set count = 4999 where id = 1; Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0
此时用户1将库存更新为4999,但是未提交事务,锁已经被释放,用户2拿到锁,开始执行相同的操作,查询数据库并更新库存:
1 2 3 4 5 6 7 8 9 10 11 12 mysql> begin; Query OK, 0 rows affected (0.00 sec) mysql> select * from db_stock where id = 1; +----+--------------+-----------+-------+ | id | product_code | warehouse | count | +----+--------------+-----------+-------+ | 1 | 1001 | 北京仓 | 5000 | +----+--------------+-----------+-------+ 1 row in set (0.00 sec) mysql> update db_stock set count = 4999 where id = 1;
可以发现,用户2获取到的库存还是5000,用户2修改的库存还是4999,这就导致一件商品被多人购买的问题,由于用户1的事务未提交,用户2的修改不能成功,在等待获取锁,当用户1执行commit;提交事务后,用户2的修改语句执行成功,此时用户2也提交事务,最终数据库的库存为4999,这也解释了为什么事务会导致jvm锁不住,商品超卖的原因。
MYSQL悲观锁 数据准备 1 2 3 4 INSERT INTO distributed_lock.db_stock (id, product_code, warehouse, count) VALUES (1, '1001', '北京仓', 5000); INSERT INTO distributed_lock.db_stock (id, product_code, warehouse, count) VALUES (2, '1001', '上海仓', 3000); INSERT INTO distributed_lock.db_stock (id, product_code, warehouse, count) VALUES (3, '1002', '上海仓', 500); INSERT INTO distributed_lock.db_stock (id, product_code, warehouse, count) VALUES (4, '1003', '贵阳仓', 8000);
原理 MySQL悲观锁的原理,是在查询的语句后添加for update来实现数据加锁,但这也势必影响到程序的效率。
我们基于上述代码继续改造,首先,在StockMapper添加一个查询方法:
1 2 @Select("select * from db_stock where product_code = #{productCode} for update") List<Stock> queryStock (String productCode) ;
其次,将StockService扣减库存的方法改造如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 @Transactional public Boolean deduction () Stock stock = stockMapper.queryStock("1001" ).get(0 ); if (stock != null && stock.getCount() > 0 ) { stock.setCount(stock.getCount() - 1 ); stockMapper.updateById(stock); log.info("库存扣减成功,余量:{}" , stock.getCount()); return true ; } log.info("库存扣减失败,库存信息:{}" , stock); return false ; }
改造完毕后,我们还是使用集群的方式部署,然后进行压力测试,测试结果如下:
可以看到,虽然是两个集群,但是吞吐量降到了311.93/s,查看数据库,库存扣减为0,符合预期,但是效率下降明显。
MYSQL乐观锁 乐观锁的实现原理是,在数据表中添加一个字段,用于做版本比较,更新的时候根据版本号判断数据是否为查询之前的数据,未被其他人修改过,如果版本号一致,那么执行更新,并且更新版本号,否则不执行更新。
我们在表中添加一个字段用于记录版本:
1 ALTER TABLE db_stock ADD COLUMN version INT DEFAULT 0 COMMENT '乐观锁版本号';
在实体Stock中添加字段version,然后改造Service中的扣减方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public Boolean deduction () Stock stock = stockMapper.queryStock("1001" ).get(0 ); if (stock != null && stock.getCount() > 0 ) { stock.setCount(stock.getCount() - 1 ); stock.setVersion(stock.getVersion() + 1 ); int res = stockMapper.update(stock, new UpdateWrapper<Stock>().eq("id" , stock.getId()).eq("version" , stock.getVersion() - 1 )); if (res == 0 ) { try { Thread.sleep(20 ); } catch (InterruptedException e) { e.printStackTrace(); } deduction(); } log.info("库存扣减成功,余量:{}" , stock.getCount()); return true ; } log.info("库存扣减失败,库存信息:{}" , stock); return false ; }
通过压力测试,可以发现,吞吐量变得更低了,只有186.30/s
其次,还需要注意,方法上不能添加事务注解,否则会导致大量异常,数据库超时,另外,重试的时候,需要对线程进行短暂休眠,否则会导致大量调用栈溢出的异常。 发现乐观锁的并发居然比悲观锁的更低了,其实压测过程中可以发现,起先吞吐量还是挺高的,由于请求越来越多,重试的也越来越多,导致了并发越高,越到后面效率越低。
Redis乐观锁 基于上述代码,继续改造,首先引入redis依赖:
1 2 3 4 <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-data-redis</artifactId > </dependency >
其次,在配置文件中添加配置项:
1 2 3 4 5 spring: redis: host: localhost port: 6379 database: 3
最后改造Service方法如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 package cn.springcoder.demo.distributed.lock.service;import lombok.extern.slf4j.Slf4j;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.dao.DataAccessException;import org.springframework.data.redis.core.RedisOperations;import org.springframework.data.redis.core.SessionCallback;import org.springframework.data.redis.core.StringRedisTemplate;import org.springframework.stereotype.Service;import java.util.List;@Service @Slf4j public class StockService @Autowired private StringRedisTemplate redisTemplate; public Boolean deduction () redisTemplate.execute(new SessionCallback<Object>() { @Override public Object execute (RedisOperations operations) throws DataAccessException operations.watch("stock" ); String stock = (String) operations.opsForValue().get("stock" ); if (stock == null || stock.length() == 0 ) { log.error("商品库存不存在" ); } else { Integer stockInt = Integer.valueOf(stock); if (stockInt > 0 ) { operations.multi(); operations.opsForValue().set("stock" , String.valueOf(--stockInt)); List exec = operations.exec(); if (exec.size() == 0 ) { try { Thread.sleep(20 ); } catch (InterruptedException e) { e.printStackTrace(); } deduction(); } log.info("库存扣减成功,余量:{}" , stockInt); return exec; } } return null ; } }); return false ; } }
最后,在redis中添加一个键值对,存储库存量数据:
1 127.0.0.1:6379[3]> set stock 5000
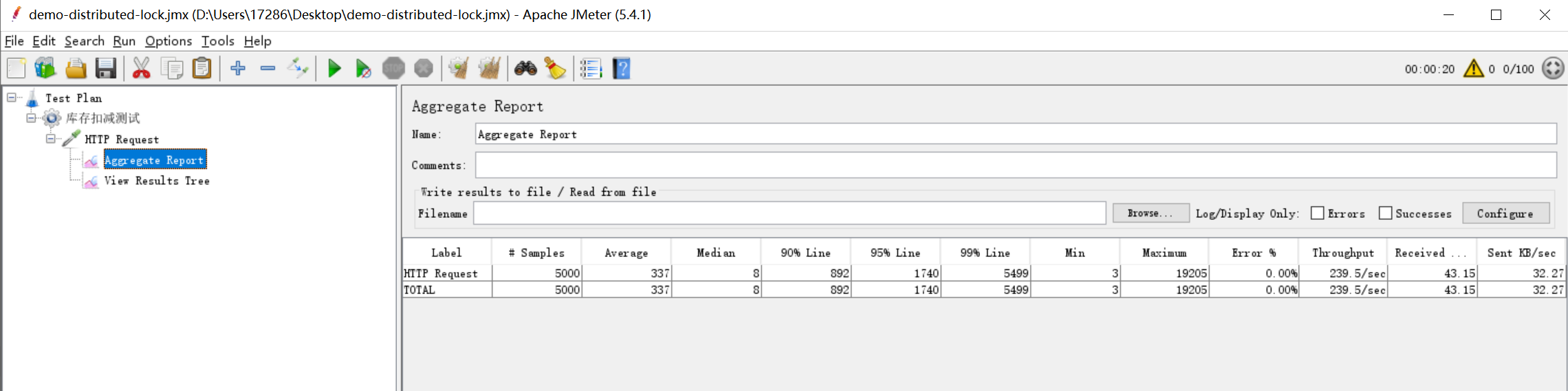
通过压力测试可以看出,这种锁的效率也并不高,两个集群,并发只有239.5/s,不推荐使用redis的乐观锁进行操作。
操作说明:watch用于监听一个或多个key值,如果在事务执行(exec)之前,被监听的数据值发生了变化,则取消事务执行。
multi开启事务,exec执行事务。
Redis分布式锁简单实现 分布式锁可以跨进程、跨服务、跨服务器。
在Redis中,有个命令可以将判断是否存在和赋值一并操作,接下来我们基于上述代码,继续改造,首先讲解下使用到的Redis命令。
1 2 3 4 127.0.0.1:6379[3]> setnx lock 1111 (integer) 1 127.0.0.1:6379[3]> setnx lock 1111 (integer) 0
可以看到,命令setnx在进行赋值时,如果key不存在,则赋值成功,返回1,否则返回0,这样我们就可以在代码中,将判断锁和获取锁放到一起执行。下面改造Service代码,然后重新将Redis中的库存量改为5000(set stock 5000),其他地方无需改动。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 package cn.springcoder.demo.distributed.lock.service;import lombok.extern.slf4j.Slf4j;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.data.redis.core.StringRedisTemplate;import org.springframework.stereotype.Service;import java.util.UUID;import java.util.concurrent.TimeUnit;@Service @Slf4j public class StockService @Autowired private StringRedisTemplate redisTemplate; public Boolean deduction () String uuid = UUID.randomUUID().toString(); Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock" , uuid, 5 , TimeUnit.SECONDS); while (lock == null || !lock) { try { Thread.sleep(30 ); lock = redisTemplate.opsForValue().setIfAbsent("lock" , uuid, 5 , TimeUnit.SECONDS); } catch (InterruptedException e) { e.printStackTrace(); } } try { String stock = redisTemplate.opsForValue().get("stock" ); if (stock != null && stock.length() > 0 ) { Integer stockInt = Integer.valueOf(stock); if (stockInt > 0 ) { redisTemplate.opsForValue().set("stock" , String.valueOf(--stockInt)); log.info("库存扣减成功,余量:{}" , stockInt); return true ; } else { log.warn("库存不足啦" ); return false ; } } } finally { if (uuid.equals(redisTemplate.opsForValue().get("lock" ))) { redisTemplate.delete("lock" ); } } return false ; } }
上述代码的改造,优化了几个方面,其中,通过对Redis锁添加过期时间,防止服务器宕机 后锁一直存在产生死锁,影响后续流程,记住,这里的过期时间,仅仅是为了防止服务器宕机,那么这个过期时间设置多长合适呢,这个没有固定值,设置短了可能业务流程都没结束,锁就被释放了,导致数据异常,设置长了,可能流程执行结束很久了,锁还没释放,还在占用资源,影响效率,后面的改造,我们会对过期时间进行续期改造,如果流程没结束,但是锁马上过期了,我们自动给锁延长过期时间,保证流程能执行结束后才释放锁,这样可保证安全与效率的兼顾。
加锁过程中,使用UUID作为键值,用于防止锁被误删除,释放锁的时候,必须先判断是自己的锁,才能释放。
另外需要注意的是,开发过程中,可能通过并发测试的时候,发现没有接口能请求成功,也没有抛出异常,那你就得检查下Redis中是否已经存在了lock这个键名,通过上述改造代码我们可以发现,如果这个键名存在,则会一致循环尝试获取锁,但是只有当这个键名被删除,才能拿得到锁。
上述的改造中可以发现,我们就之前的递归调用,改成了循环获取锁,这样可以有效避免递归过多导致的调用栈溢出问题。
通过压测,发现数据扣减符合预期,锁能满足要求,但是并发量只有355.4/s,并不算高。
通过Lua脚本解决释放锁的原子性问题 上述的代码改造中,在释放锁的时候,可以看到是两条语句完成的,首先读取数据,判断是不是自己的锁,然后再进行锁的释放,这就必然存在原子性的问题。
Redis中,我们可以通过命令eval来执行lua脚本,格式如下:
1 eval script numkeys key [key ...] arg [arg ...]
参数解释如下:
script:是需要执行的lua脚本语句,结果需要通过return返回;
numkeys:参数名称的数量,需要传递几个参数,就是数值几;
key:参数名称,多个参数以空格分隔;
arg:参数值,多个值以空格分隔。
参数名通过数组KEYS获取,下标从1开始,参数值通过数组ARGV获取,下标从1开始。
下面举例说明,比如,判断Redis中如果键lock对应的值为1111,那么返回1,否则返回0:
1 2 3 4 5 6 127.0.0.1:6379[3]> eval "if redis.call('get', KEYS[1])==ARGV[1] then return 1 else return 0 end" 1 lock 1111 (integer) 0 127.0.0.1:6379[3]> set lock 1111 OK 127.0.0.1:6379[3]> eval "if redis.call('get', KEYS[1])==ARGV[1] then return 1 else return 0 end" 1 lock 1111 (integer) 1
基于上述代码,改造释放锁的逻辑,我们只需要将上述代码中,finally里面的代码块改为如下即可:
1 2 3 4 5 6 7 8 import org.springframework.data.redis.core.script.DefaultRedisScript;import java.util.Arrays;String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end" ; redisTemplate.execute(new DefaultRedisScript<>(script, Boolean.class), Arrays.asList("lock" ), uuid);
可重入锁 实际业务中,加锁的流程可能是复杂的,比如嵌套。举个例子,在调用方法A的时候,方法体里面需要加锁处理,在A的方法体中,又调用了方法B,同样的,方法B的方法体中,也需要加锁处理,如果锁是同一个,且不支持重入的话,会出现死锁问题,因为A的方法执行需要调用B方法,但是B方法的执行需要得到锁,此时锁被A方法占用,B一直得不到锁,就出现了死锁。
正常的逻辑应该是,B方法要能正常的得到锁,后续的流程才能正常执行。那么什么是可重入锁呢,以上述例子说明,可重入锁就是,A方法得到锁后,调用B方法,B方法能正常拿到锁,并且B方法释放锁后,不会把A方法的锁释放掉。
根据上述思路,参考JDK的ReentrantLock锁,实现可重入锁,我们需要两个变量去记录数据,一个int类型的变量count用于记录重入次数,一个String类型的变量lockId用于记录得到锁的线程信息(可以是线程id,或者直接用线程对象),获取锁的时候,先判断锁是否存在,如果不存在,则得到锁,将count设置为1,并记录lockId。后续如果嵌套调用中,还需要获取这个锁,就可以判断lockId是否一致,一致即认为是同一个线程,可重入,将count自增1,同理,嵌套方法调用结束,释放锁时,将count减一,直到count变为0,既是锁被完全释放。
Lua脚本可重入锁加锁 下面,通过Lua脚本实现可重入锁的一个加锁流程:
1 2 3 4 5 6 7 if redis.call('exists' , 'lock' )==0 or redis.call('hexists' , 'lock' , 'lockid01' )==1 then redis.call('hincrby' , 'lock' , 'lockid01' , 1 ) redis.call('expire' , 'lock' , 5 ) return 1 else return 0 end
上述代码,简单实现了重入锁的逻辑,如果锁不存在,或者存在当前锁,则通过命令hincrby将重入次数自增1,并且设置锁的过期时间,返回成功,否则返回获取锁失败。这里还使用了Redis的hash数据类型,用于简化操作。重入一次重置一次锁的过期时间,防止嵌套过多,锁被提前释放。基于以上脚本,我们将参数提取出来,在Redis中执行演示,如下:
1 2 3 4 5 6 127.0.0.1:6379[3]> eval "if redis.call('exists', KEYS[1])==0 or redis.call('hexists', KEYS[1], ARGV[1])==1 then redis.call('hincrby', KEYS[1], ARGV[1], 1) redis.call('expire', KEYS[1], ARGV[2]) return 1 else return 0 end" 1 lock id01 20 (integer) 1 127.0.0.1:6379[3]> eval "if redis.call('exists', KEYS[1])==0 or redis.call('hexists', KEYS[1], ARGV[1])==1 then redis.call('hincrby', KEYS[1], ARGV[1], 1) redis.call('expire', KEYS[1], ARGV[2]) return 1 else return 0 end" 1 lock id01 20 (integer) 1 127.0.0.1:6379[3]> hget lock id01 "2"
Lua脚本可重入锁解锁 释放锁的逻辑为,首先判断自己的锁是否存在,如果不存在直接返回nil,锁存在,则执行减一操作,判断减一后的数值是否为0,如果为0,表示锁释放成功,执行命令del删除锁,返回1,不为0表示锁被释放了一次,还有其他重入的地方需要释放,返回0,下面是Lua脚本的实现逻辑:
1 2 3 4 5 6 7 8 9 if redis.call('hexists' , 'lock' , 'lockid01' ) == 0 then return nil elseif redis.call('hincrby' , 'lock' , 'lockid01' , -1 ) == 0 then return redis.call('del' , 'lock' ) else return 0 end
同样,我们将参数提取出来,在Redis客户端进行测试:
1 2 127.0.0.1:6379[3]> eval "if redis.call('hexists', KEYS[1], ARGV[1]) == 0 then return nil elseif redis.call('hincrby', KEYS[1], ARGV[1], -1) == 0 then return redis.call('del', KEYS[1]) else return 0 end" 1 lock lockid01 (integer) 1
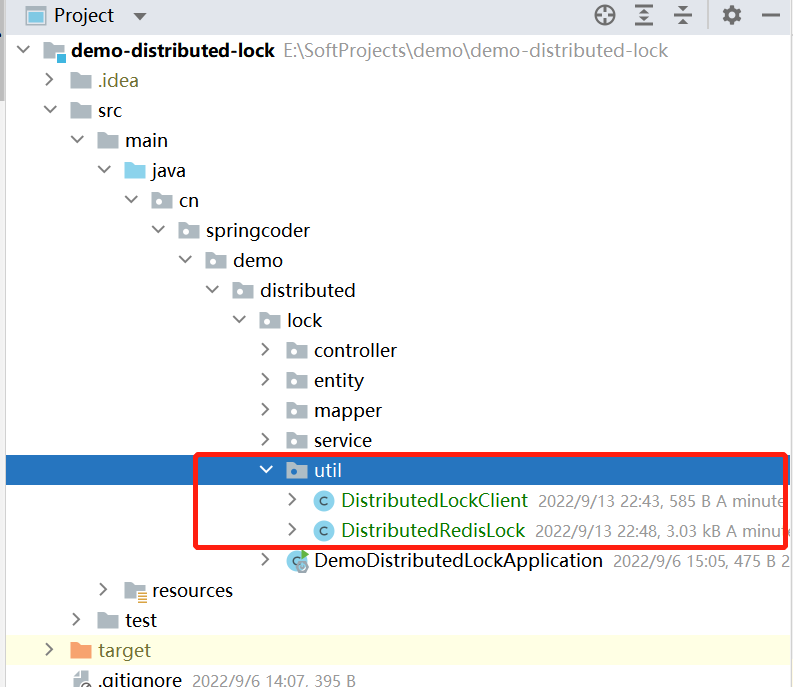
可重入锁的代码实现 基于上述代码改造,我们增加两个类,DistributedRedisLock和DistributedLockClient,一个是锁的逻辑实现,一个是获取对象的工厂工具类,代码路径如下图:
类DistributedRedisLock的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 package cn.springcoder.demo.distributed.lock.util;import org.jetbrains.annotations.NotNull;import org.springframework.data.redis.core.StringRedisTemplate;import org.springframework.data.redis.core.script.DefaultRedisScript;import java.util.Collections;import java.util.concurrent.TimeUnit;import java.util.concurrent.locks.Condition;import java.util.concurrent.locks.Lock;public class DistributedRedisLock implements Lock private StringRedisTemplate redisTemplate; private String lockName; private String uuid; private long expire = 30 ; public DistributedRedisLock (StringRedisTemplate redisTemplate, String lockName, String uuid) this .redisTemplate = redisTemplate; this .lockName = lockName; this .uuid = uuid; } @Override public void lock () this .tryLock(); } @Override public void lockInterruptibly () throws InterruptedException } @Override public boolean tryLock () try { return tryLock(-1L , TimeUnit.SECONDS); } catch (InterruptedException e) { e.printStackTrace(); return false ; } } @Override public boolean tryLock (long time, @NotNull TimeUnit unit) throws InterruptedException if (time != -1 ) { this .expire = TimeUnit.DAYS.toSeconds(time); } String script = "if redis.call('exists', KEYS[1]) == 0 or redis.call('hexists', KEYS[1], ARGV[1]) == 1 " + "then" + " redis.call('hincrby', KEYS[1], ARGV[1], 1) " + " redis.call('expire', KEYS[1], ARGV[2]) " + " return 1 " + "else" + " return 0 " + "end" ; while (Boolean.FALSE.equals(redisTemplate.execute(new DefaultRedisScript<>(script, Boolean.class), Collections.singletonList(lockName), getId(), String.valueOf(this .expire)))) { Thread.sleep(20 ); } return true ; } @Override public void unlock () String script = "if redis.call('hexists', KEYS[1], ARGV[1]) == 0 " + "then " + " return nil " + "elseif redis.call('hincrby', KEYS[1], ARGV[1], -1) == 0 " + "then " + " return redis.call('del', KEYS[1]) " + "else " + " return 0 " + "end" ; Long execute = redisTemplate.execute(new DefaultRedisScript<>(script, Long.class), Collections.singletonList(lockName), getId()); if (execute == null ) { throw new IllegalMonitorStateException("This lock doesn't belong to you!" ); } } @NotNull @Override public Condition newCondition () return null ; } String getId () { return uuid + ":" + Thread.currentThread().getId(); } }
类DistributedLockClient的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 package cn.springcoder.demo.distributed.lock.util;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.data.redis.core.StringRedisTemplate;import org.springframework.stereotype.Component;import java.util.UUID;@Component public class DistributedLockClient @Autowired private StringRedisTemplate redisTemplate; private final String uuid; public DistributedLockClient () this .uuid = UUID.randomUUID().toString(); } public DistributedRedisLock getRedisLock (String lockName) return new DistributedRedisLock(redisTemplate, lockName, uuid); } }
Service代码改造后如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 package cn.springcoder.demo.distributed.lock.service;import cn.springcoder.demo.distributed.lock.util.DistributedLockClient;import lombok.extern.slf4j.Slf4j;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.data.redis.core.StringRedisTemplate;import org.springframework.stereotype.Service;import java.util.concurrent.locks.Lock;@Service @Slf4j public class StockService @Autowired private StringRedisTemplate redisTemplate; @Autowired private DistributedLockClient lockClient; public Boolean deduction () Lock lock = lockClient.getRedisLock("lock" ); lock.lock(); try { this .testReentrant(); String stock = redisTemplate.opsForValue().get("stock" ); if (stock != null && stock.length() > 0 ) { Integer stockInt = Integer.valueOf(stock); if (stockInt > 0 ) { redisTemplate.opsForValue().set("stock" , String.valueOf(--stockInt)); log.info("库存扣减成功,余量:{}" , stockInt); return true ; } else { log.warn("库存不足啦" ); return false ; } } } finally { lock.unlock(); } return false ; } public void testReentrant () Lock lock = lockClient.getRedisLock("lock" ); lock.lock(); try { log.info("可重入锁测试" ); } finally { lock.unlock(); } } }
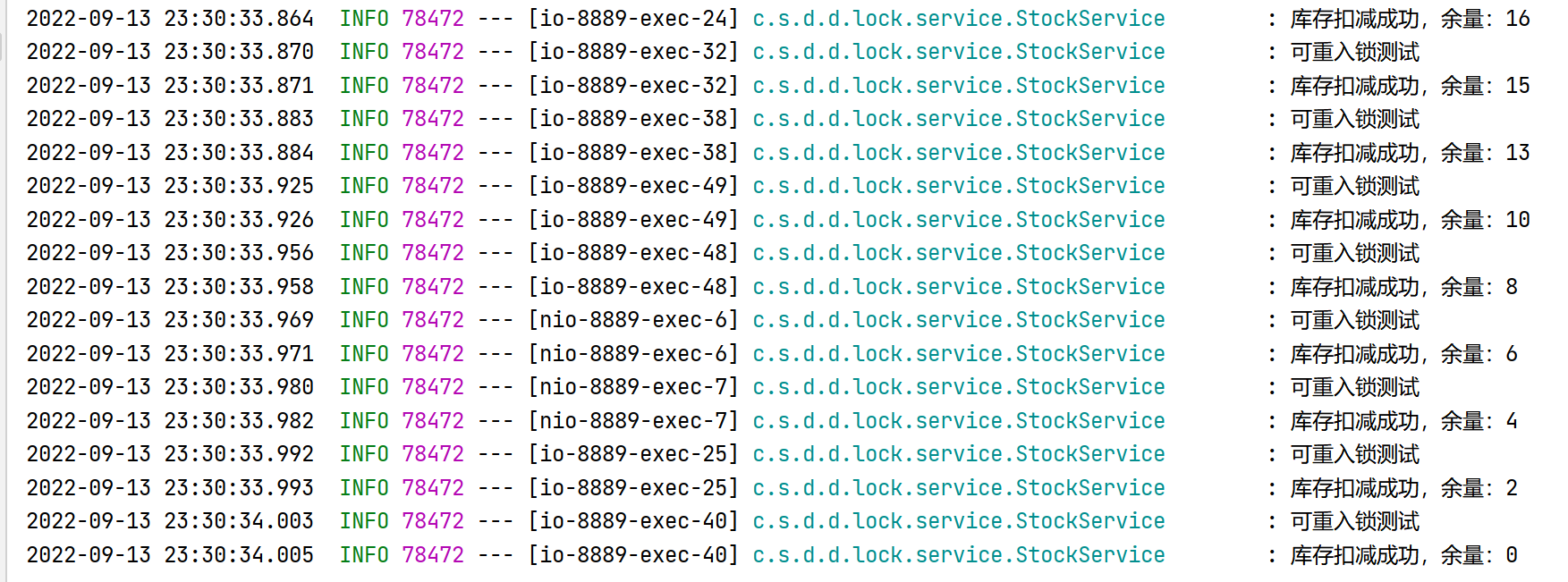
使用压测工具测试,可以看到控制台的输出正常,查看redis中的库存余量为0,符合预期,并且通过断点调试测试发现,锁重入成功。
自动续期 实现逻辑 基于定时任务(Timer),给锁自动续期,每隔一定周期,判断是自己的锁,则重置过期时间。lua脚本实现如下:
1 2 3 4 5 6 if redis.call('hexists' , KEYS[1 ], ARGV[1 ]) == 1 then return redis.call('expire' , KEYS[1 ], ARGV[2 ]) else return 0 end
这里有一个参数名,两个参数,参数名为锁的名称,参数为锁的id和过期时间,下面在redis客户端执行一下脚本测试。
1 2 3 4 5 6 127.0.0.1:6379[3]> hset lock a 3 (integer) 1 127.0.0.1:6379[3]> eval "if redis.call('hexists', KEYS[1], ARGV[1]) == 1 then return redis.call('expire', KEYS[1], ARGV[2]) else return 0 end" 1 lock a 30 (integer) 1 127.0.0.1:6379[3]> ttl lock (integer) 27
可以看到,过期时间被重置。
实现代码 有了上述的lua脚本实现逻辑,通过代码实现也就容易了,基于之前的代码,我们继续改造,给锁添加自动续期逻辑。
首先,我们测试一下没有自动续期的锁是什么效果,直接在原来的代码上,给扣减库存方法,获取到锁后线程休眠400秒Thread.sleep(400000);,然后我们可以在redis客户端通过命令ttl lock查看锁的过期时间,由30秒到直接过期,锁被释放,但实际业务流程还未处理完毕,这会由提前释放锁导致一系列问题。
类DistributedRedisLock代码改造如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 package cn.springcoder.demo.distributed.lock.util;import org.jetbrains.annotations.NotNull;import org.springframework.data.redis.core.StringRedisTemplate;import org.springframework.data.redis.core.script.DefaultRedisScript;import java.util.Collections;import java.util.Timer;import java.util.TimerTask;import java.util.concurrent.TimeUnit;import java.util.concurrent.locks.Condition;import java.util.concurrent.locks.Lock;public class DistributedRedisLock implements Lock private StringRedisTemplate redisTemplate; private String lockName; private String uuid; private long expire = 30 ; public DistributedRedisLock (StringRedisTemplate redisTemplate, String lockName, String uuid) this .redisTemplate = redisTemplate; this .lockName = lockName; this .uuid = uuid + ":" + Thread.currentThread().getId(); } @Override public void lock () this .tryLock(); } @Override public void lockInterruptibly () throws InterruptedException } @Override public boolean tryLock () try { return tryLock(-1L , TimeUnit.SECONDS); } catch (InterruptedException e) { e.printStackTrace(); return false ; } } @Override public boolean tryLock (long time, @NotNull TimeUnit unit) throws InterruptedException if (time != -1 ) { this .expire = TimeUnit.DAYS.toSeconds(time); } String script = "if redis.call('exists', KEYS[1]) == 0 or redis.call('hexists', KEYS[1], ARGV[1]) == 1 " + "then" + " redis.call('hincrby', KEYS[1], ARGV[1], 1) " + " redis.call('expire', KEYS[1], ARGV[2]) " + " return 1 " + "else" + " return 0 " + "end" ; while (Boolean.FALSE.equals(redisTemplate.execute(new DefaultRedisScript<>(script, Boolean.class), Collections.singletonList(lockName), uuid, String.valueOf(this .expire)))) { Thread.sleep(20 ); } this .renewExpire(); return true ; } @Override public void unlock () String script = "if redis.call('hexists', KEYS[1], ARGV[1]) == 0 " + "then " + " return nil " + "elseif redis.call('hincrby', KEYS[1], ARGV[1], -1) == 0 " + "then " + " return redis.call('del', KEYS[1]) " + "else " + " return 0 " + "end" ; Long execute = redisTemplate.execute(new DefaultRedisScript<>(script, Long.class), Collections.singletonList(lockName), uuid); if (execute == null ) { throw new IllegalMonitorStateException("This lock doesn't belong to you!" ); } } @NotNull @Override public Condition newCondition () return null ; } public void renewExpire () String script = "if redis.call('hexists', KEYS[1], ARGV[1]) == 1 " + "then " + " return redis.call('expire', KEYS[1], ARGV[2]) " + "else " + " return 0 " + "end" ; new Timer().schedule(new TimerTask() { @Override public void run () if (Boolean.TRUE.equals(redisTemplate.execute(new DefaultRedisScript<>(script, Boolean.class), Collections.singletonList(lockName), uuid, String.valueOf(expire)))) { renewExpire(); } } }, expire * 1000 / 3 ); } }
可以看到,改造的时候,我们删除了getId()方法,这是因为,我们的自动续期方法renewExpire()是通过一个新线程来执行的,如果通过之前的getId()方法获取uuid,势必会导致线程id不一致的问题,相当于获取到的不是自己的锁,也就无法自动续期,因此,删除了getId()方法,将锁的标识存储到uuid属性,赋值的时候就已经拼接好,后续直接调用即可。
自动续期方法中,使用的Timer().schedule只是延迟过期时间(expire)的1/3时长后重置一下过期时间,如果重置成功,再调用renewExpire()方法进行重置,实现无限期自动续期。
上述代码改造完毕,我们只需在service中轻微改动,即可测试自动续期是否成功,StockService方法代码改造如下,只是在业务逻辑中添加了400秒的休眠,模拟超长耗时:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public Boolean deduction () Lock lock = lockClient.getRedisLock("lock" ); lock.lock(); try { Thread.sleep(400000 ); String stock = redisTemplate.opsForValue().get("stock" ); if (stock != null && stock.length() > 0 ) { Integer stockInt = Integer.valueOf(stock); if (stockInt > 0 ) { redisTemplate.opsForValue().set("stock" , String.valueOf(--stockInt)); log.info("库存扣减成功,余量:{}" , stockInt); return true ; } else { log.warn("库存不足啦" ); return false ; } } } catch (InterruptedException e) { e.printStackTrace(); } finally { lock.unlock(); } return false ; }
发起请求进行测试,此时进入redis客户端,通过命令查看锁的过期时间,可以发现,每当过期时间到20秒后,又自动重置为30秒,说明自动续期成功。
1 2 3 4 5 6 7 8 127.0.0.1:6379[3]> ttl lock (integer) 22 127.0.0.1:6379[3]> ttl lock (integer) 21 127.0.0.1:6379[3]> ttl lock (integer) 30 127.0.0.1:6379[3]> ttl lock (integer) 25
Redis分布式锁的总结
独占排他:setnx
防死锁:通过设置过期时间防宕机,通过可重入防死锁;
防误删:确认是自己的锁才能释放;
原子性:加锁和过期时间之间的原子性,判断和释放锁之间的原子性;
可重入性:hash + lua脚本
自动续期:Timer定时器 + lua脚本。
Redisson分布式锁 通过上述的渐进讲解,我们实现了一个简单的手写分布式锁,但是功能比较简单,实际使用起来可能还是不那么顺手,下面我们介绍一个开源的分布式锁工具,基于redis实现可重入分布式锁的工具。GitHub主页地址:GitHub - redisson/redisson: Redisson - Redis Java client with features of In-Memory Data Grid. Over 50 Redis based Java objects and services: Set, Multimap, SortedSet, Map, List, Queue, Deque, Semaphore, Lock, AtomicLong, Map Reduce, Publish / Subscribe, Bloom filter, Spring Cache, Tomcat, Scheduler, JCache API, Hibernate, MyBatis, RPC, local cache …
引入依赖 1 2 3 4 5 <dependency > <groupId > org.redisson</groupId > <artifactId > redisson</artifactId > <version > 3.17.6</version > </dependency >
创建配置类RedissonConfig 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 package cn.springcoder.demo.distributed.lock.config;import org.redisson.Redisson;import org.redisson.api.RedissonClient;import org.redisson.config.Config;import org.springframework.boot.autoconfigure.data.redis.RedisProperties;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;@Configuration public class RedissonConfig @Bean public RedissonClient redissonClient (RedisProperties redisProperties) Config config = new Config(); config.useSingleServer() .setAddress(String.join("" , "redis://" , redisProperties.getHost(), ":" , String.valueOf(redisProperties.getPort()))) .setDatabase(3 ) .setConnectionMinimumIdleSize(10 ) .setConnectionPoolSize(50 ) .setConnectTimeout(60000 ); return Redisson.create(config); } }
通过上述配置,我们可以通过SpringBoot的自动配置RedisProperties读取yml或properties文件中的redis连接信息。
这里我们使用的是程序的方式来配置,也可以在yml配置文件中进行配置,更多配置方式,参考官方文档:2. 配置方法 · redisson/redisson Wiki · GitHub
改造Service 我们改造service中的方法,使用Redisson分布式锁来解决超卖问题。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 package cn.springcoder.demo.distributed.lock.service;import lombok.extern.slf4j.Slf4j;import org.redisson.api.RLock;import org.redisson.api.RedissonClient;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.data.redis.core.StringRedisTemplate;import org.springframework.stereotype.Service;@Service @Slf4j public class StockService @Autowired private StringRedisTemplate redisTemplate; @Autowired private RedissonClient redissonClient; public Boolean deduction () RLock lock = redissonClient.getLock("lock" ); lock.lock(); try { String stock = redisTemplate.opsForValue().get("stock" ); if (stock != null && stock.length() > 0 ) { Integer stockInt = Integer.valueOf(stock); if (stockInt > 0 ) { redisTemplate.opsForValue().set("stock" , String.valueOf(--stockInt)); log.info("库存扣减成功,余量:{}" , stockInt); return true ; } else { log.warn("库存不足啦" ); return false ; } } } finally { lock.unlock(); } return false ; } }
通过压测工具进行测试,我们可以发现,商品库存扣减符合预期,没有出现超卖问题,说明Redisson分布式锁达到目的,使用中可以发现,该工具使用简单,只需简单配置,即可上手使用,并且还有更多方便的功能可使用。
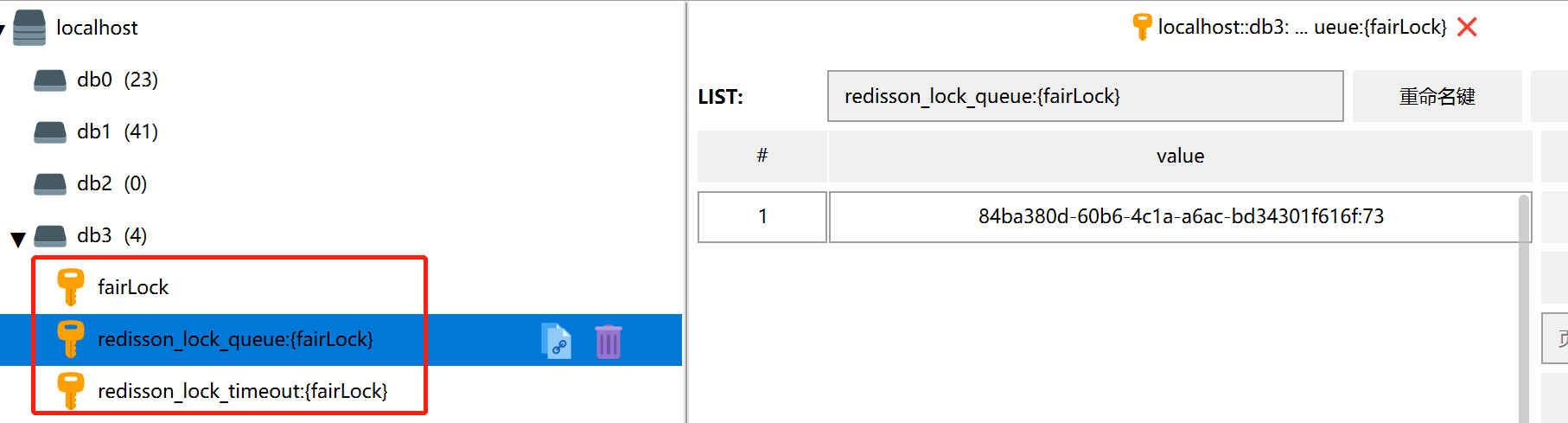
Redisson之FairLock公平锁 基于Redis的Redisson分布式可重入公平锁也是实现了java.util.concurrent.locks.Lock接口的一种RLock对象。同时还提供了异步(Async) 、反射式(Reactive) 和RxJava2标准 的接口。它保证了当多个Redisson客户端线程同时请求加锁时,优先分配给先发出请求的线程。所有请求线程会在一个队列中排队,当某个线程出现宕机时,Redisson会等待5秒后继续下一个线程,也就是说如果前面有5个线程都处于等待状态,那么后面的线程会等待至少25秒。
1 2 3 RLock fairLock = redisson.getFairLock("anyLock" ); fairLock.lock();
另外Redisson还通过加锁的方法提供了leaseTime的参数来指定加锁的时间。超过这个时间后锁便自动解开了。
1 2 3 4 5 6 7 8 fairLock.lock(10 , TimeUnit.SECONDS); boolean res = fairLock.tryLock(100 , 10 , TimeUnit.SECONDS);... fairLock.unlock();
Redisson同时还为分布式可重入公平锁提供了异步执行的相关方法:
1 2 3 4 RLock fairLock = redisson.getFairLock("anyLock" ); fairLock.lockAsync(); fairLock.lockAsync(10 , TimeUnit.SECONDS); Future<Boolean> res = fairLock.tryLockAsync(100 , 10 , TimeUnit.SECONDS);
非公平锁代码测试 接下来,我们通过代码来测试Redisson的公平锁与非公平锁,首先在Controller增加方法testUnfairLock用于接收请求,在Service增加具体测试非公平锁的测试代码,Controller中增加的方法代码如下:
1 2 3 4 5 @GetMapping("testUnfairLock/{id}") public String testUnfairLock (@PathVariable Long id) stockService.testUnfairLock(id); return "Hello unfair lock!" ; }
Service中增加的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 public void testUnfairLock (Long id) RLock unfairLock = redissonClient.getLock("unfairLock" ); try { unfairLock.lock(); log.info("非公平锁测试==========={}" , id); TimeUnit.SECONDS.sleep(10 ); } catch (InterruptedException e) { e.printStackTrace(); } finally { unfairLock.unlock(); } }
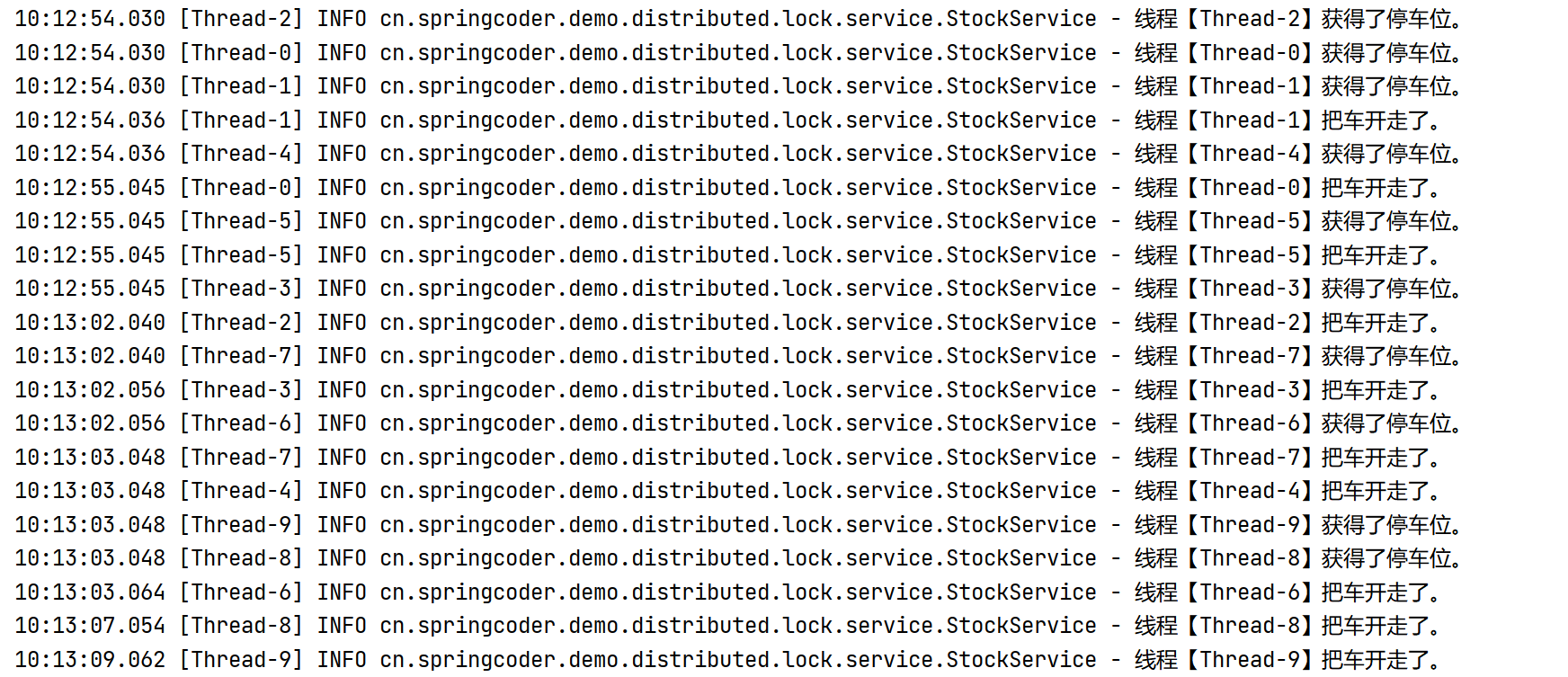
然后我们部署两个集群,通过浏览器访问,依次将参数id从1到5进行请求(无需等待请求响应,即发出下一个请求),然后在控制台中进行观测,可以发现,控制台中打印出来的id顺序,并不与请求顺序相同,说明通过redissonClient.getLock("unfairLock");获取到的锁是非公平锁。
FairLock公平锁测试 在上述代码的基础上,我们在Controller和Service继续增加一个方法,用于测试公平锁,Controller中增加的方法代码如下:
1 2 3 4 5 @GetMapping("testFairLock/{id}") public String testFairLock (@PathVariable Long id) stockService.testFairLock(id); return "Hello fair lock!" ; }
Service中增加的方法代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 public void testFairLock (Long id) RLock fairLock = redissonClient.getFairLock("fairLock" ); try { fairLock.lock(); log.info("公平锁测试==========={}" , id); TimeUnit.SECONDS.sleep(10 ); } catch (InterruptedException e) { e.printStackTrace(); } finally { fairLock.unlock(); } }
然后我们在浏览器中发起请求测试,依次将参数id从1递增至5,然后观测控制台打印的日志信息。由于是集群部署,这里看到的截图可能不是那么直观,但是自己在控制台查看,可以明显的发现,使用公平锁之后,打印的id顺序与请求顺序保持一致,说明公平锁就是先到先得,下面是控制台的日志截图:
Redisson是如何实现公平锁的呢,我们通过Redis中的键值对可以发现,是使用了队列的方式,实现先到先得的公平锁,同时,还给队列中的每个项设置了过期时间。
Redisson之RReadWriteLock读写锁 基于Redis的Redisson分布式可重入读写锁RReadWriteLockjava.util.concurrent.locks.ReadWriteLock接口。其中读锁和写锁都继承了RLock 接口。
分布式可重入读写锁允许同时有多个读锁和一个写锁处于加锁状态。
1 2 3 4 5 RReadWriteLock rwlock = redisson.getReadWriteLock("anyRWLock" ); rwlock.readLock().lock(); rwlock.writeLock().lock();
我们知道,读与读是可以并发的,读与写、写与写是不可并发的,为了提升程序的效率,将读锁与写锁分开加锁,一定程度上能提升程序的效率。
RReadWriteLock读写锁的代码测试 在Controller中增加两个方法,用于读锁与写锁的测试:
1 2 3 4 5 6 7 8 9 10 11 @GetMapping("testReadLock") public String testReadLock () stockService.testReadLock(); return "Hello read lock!" ; } @GetMapping("testWriteLock") public String testWriteLock () stockService.testWriteLock(); return "Hello write lock!" ; }
在Service中增加两个方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public void testReadLock () RReadWriteLock readWriteLock = redissonClient.getReadWriteLock("readWriteLock" ); try { readWriteLock.readLock().lock(); log.info("读锁测试" ); TimeUnit.SECONDS.sleep(10 ); } catch (InterruptedException e) { e.printStackTrace(); } finally { readWriteLock.readLock().unlock(); } } public void testWriteLock () RReadWriteLock readWriteLock = redissonClient.getReadWriteLock("readWriteLock" ); try { readWriteLock.writeLock().lock(); log.info("写锁测试" ); TimeUnit.SECONDS.sleep(10 ); } catch (InterruptedException e) { e.printStackTrace(); } finally { readWriteLock.writeLock().unlock(); } }
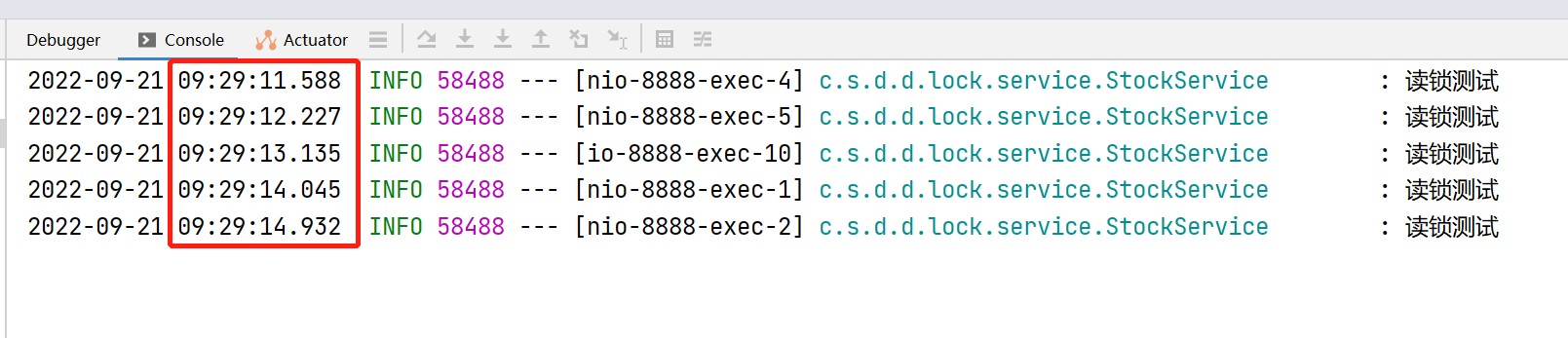
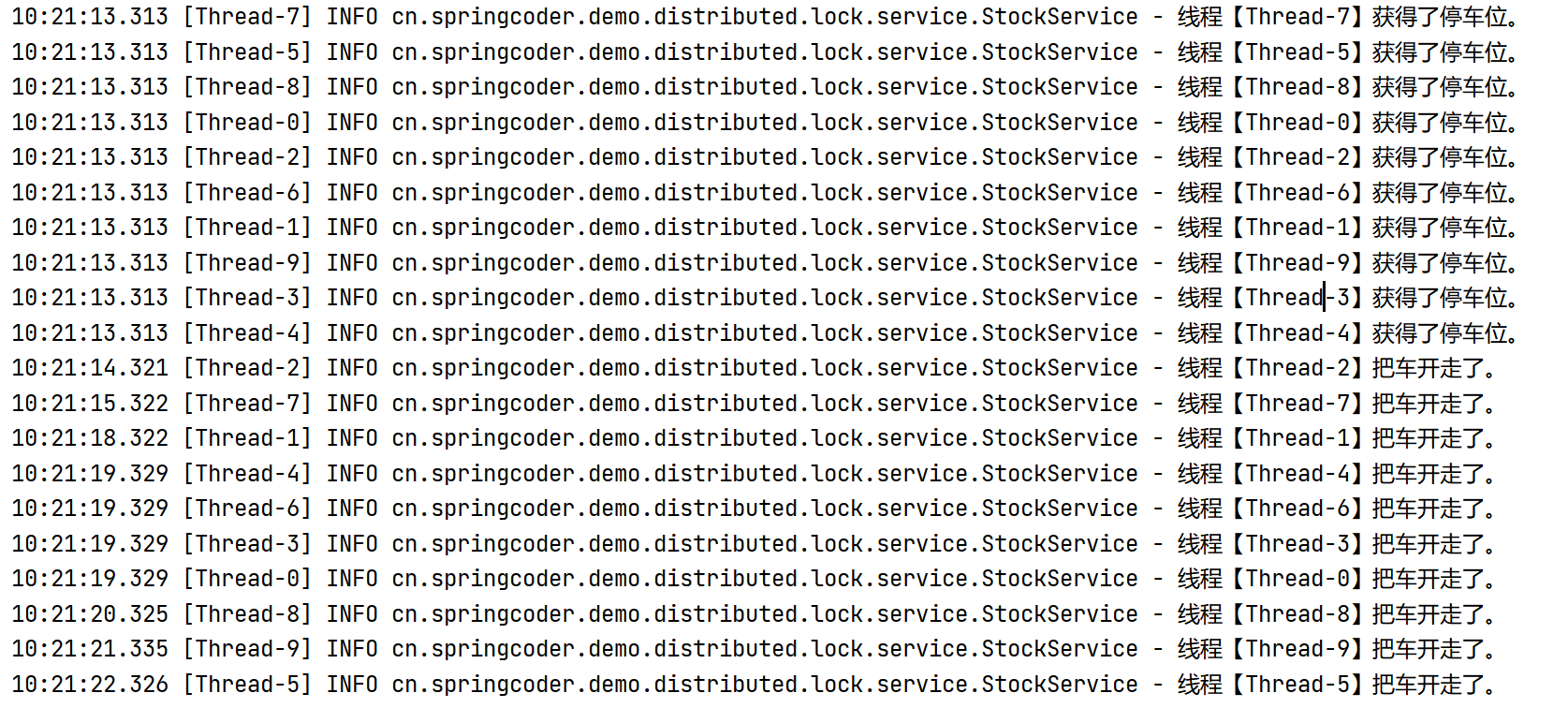
首先,我们在浏览器发出对读锁接口的请求测试,可以发现,5次请求在5秒内响应结束,并没有每个请求等待10秒,说明读与读的请求并发执行了。
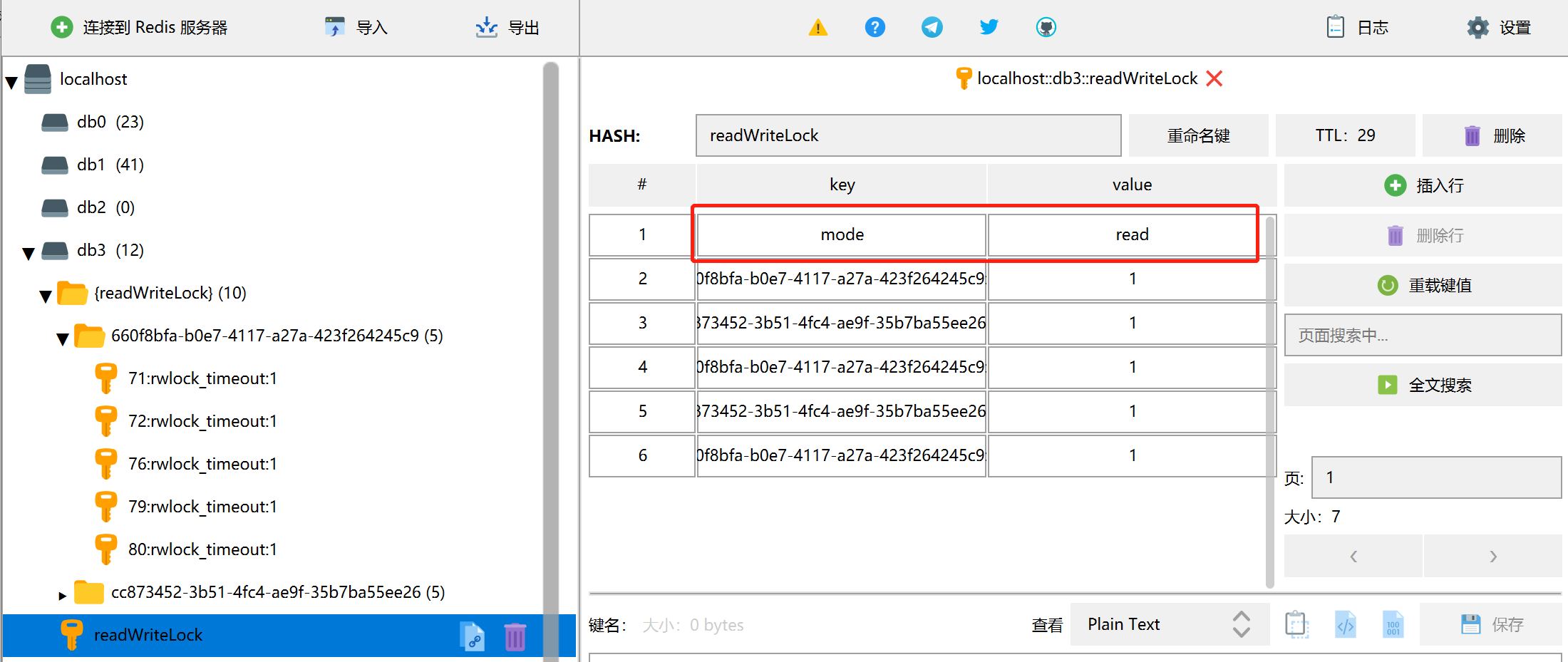
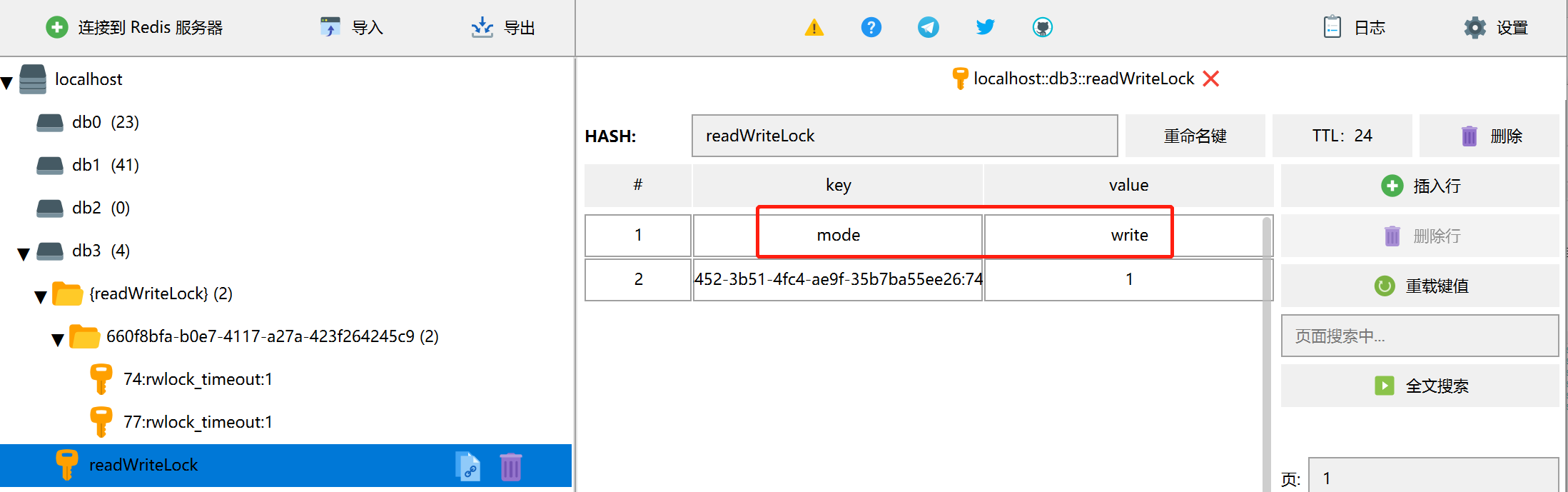
此时,我们观测Redis中键值对,可以发现锁的hash里面有一个属性mode=read。
接下来,我们先对读锁接口发出几次请求,再请求两次写锁,再请求读锁,看看测试结果。
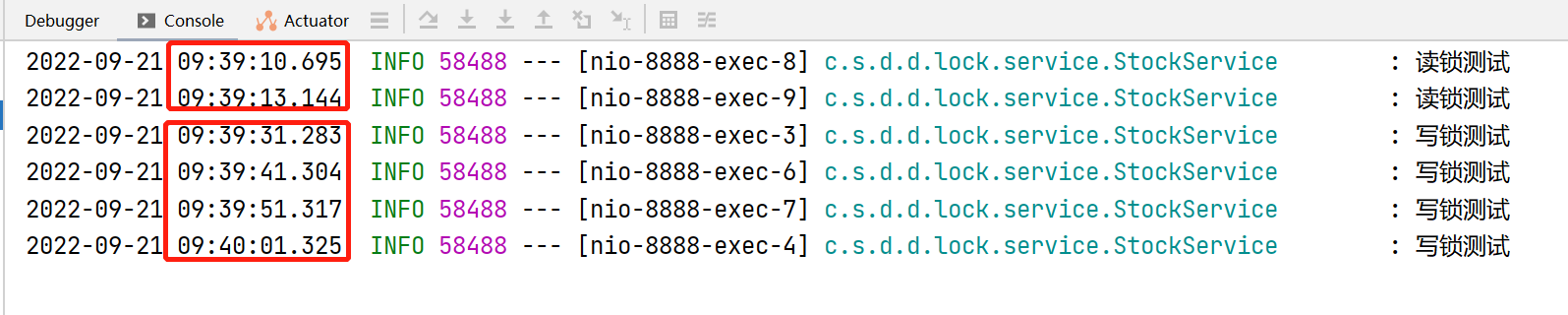
可以看到,读锁同样被并发执行,但是写锁,每个写的请求都被等待了10秒钟才响应结束,说明写锁不能并发,这样将读写锁区分开来,在某些场景下,能一定程度提高程序的并发率。观测redis中的键值对,可以发现mode在read与write之间变化,用于区分当前是读锁还是写锁。
在使用过程中一定要注意,通过redissonClient.getReadWriteLock()方法对读与写进行加锁,锁的名称一定要一致,保证拿到的是同一把锁,才能实现读写锁,否则拿到的不是一把锁,也锁不住。可观察上述读写锁Service中两个方法的测试代码,锁的名称是一样的。
Rredisson之信号量(Semaphore) 维基百科信号量的定义
信号量 (英语:semaphore )又称为信号标 ,是一个同步对象,用于保持在0至指定最大值之间的一个计数值。当线程完成一次对该semaphore对象的等待(wait)时,该计数值减一;当线程完成一次对semaphore对象的释放(release)时,计数值加一。当计数值为0,则线程等待该semaphore对象不再能成功直至该semaphore对象变成signaled状态。semaphore对象的计数值大于0,为signaled状态;计数值等于0,为nonsignaled状态。
信号量的概念是由荷兰 计算机科学家艾兹赫尔·戴克斯特拉 (Edsger W. Dijkstra)发明的[1] ,广泛的应用于不同的操作系统 中。在系统中,给予每一个行程 一个信号量,代表每个行程目前的状态,未得到控制权的行程会在特定地方被强迫停下来,等待可以继续进行的讯号到来。如果信号量是一个任意的整数,通常被称为计数讯号量(Counting semaphore),或一般讯号量(general semaphore);如果信号量只有二进位的0或1,称为二进位讯号量(binary semaphore)。
信号量的举例说明 我们可以用现实生活中的事情来举例说明,更加直观的理解信号量。比如停车场的车位是有限的,来停车的车辆数超过了车位数,停车场的大爷会在入口放个牌:车位已满!这个步骤就是对资源的访问进行了限制,那么其他车辆只能等待,等待有车辆离开(释放资源),后面排队的车才能获取到停车位。
又比如,去银行办理业务,银行的窗口只有3个,办理业务的人呢有10个,那必然会有7个人需要排队等待,等某个窗口的人业务办理结束,离开窗口(释放资源),排队的人才能有机会办理业务(获得资源占用),直到所有人的业务都办理完毕。如果资源有限,抢占资源的人很多,并且不加控制,那么极有可能会导致系统的崩溃,比如路口没有红绿灯,大家都不礼让,势必会导致堵车;银行窗口有限,大家都不排队,可能谁都无法办理业务,大家都在争抢。秒杀系统中,我们最大只允许1000个人进来秒杀,如果不加控制,可能一下子并发了10000人,那可能会导致系统的崩溃,或是引发其他的错误问题。
JDK自带的信号量演示 在Java程序中,我们可以使用JDK自带的信号量java.util.concurrent.Semaphore实现资源控制,下面使用一个main方法,简单模拟停车场停车的流程。首先,我们定义停车场只有3个车位,有10个人来停车,我们先看一下不用信号量控制的结果。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public static void main (String[] args) for (int i = 0 ; i < 10 ; i++) { new Thread(() -> { try { log.info("线程【{}】获得了停车位。" , Thread.currentThread().getName()); TimeUnit.SECONDS.sleep((long ) (Math.random() * 10 )); log.info("线程【{}】把车开走了。" , Thread.currentThread().getName()); } catch (InterruptedException e) { e.printStackTrace(); } }).start(); } }
通过日志可以发现,资源的占用显然不合理,车位只有3个,但是10个线程进来都抢到了资源,很明显不符合逻辑。下面我们改造下代码,加入信号量,控制资源的占用与释放。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public static void main (String[] args) Semaphore semaphore = new Semaphore(3 ); for (int i = 0 ; i < 10 ; i++) { new Thread(() -> { try { semaphore.acquire(); log.info("线程【{}】获得了停车位。" , Thread.currentThread().getName()); TimeUnit.SECONDS.sleep((long ) (Math.random() * 10 )); log.info("线程【{}】把车开走了。" , Thread.currentThread().getName()); semaphore.release(); } catch (InterruptedException e) { e.printStackTrace(); } }).start(); } }
通过日志我们可以看出来,使用信号量之后,资源得到了控制,资源的占用有序进行,释放一个资源,其他线程才能拿到。但是JDK自带的信号量也有弊端,只能单机使用,原因与ReentrantLock一样,不能跨服务,也就是无法满足分布式的控制,当我们的项目使用集群部署的时候,信号量的控制就会出现问题,这里就不做详细的演示了。
基于Redis的Redisson的分布式信号量(Semaphore )Java对象RSemaphore采用了与java.util.concurrent.Semaphore相似的接口和用法。同时还提供了异步(Async) 、反射式(Reactive) 和RxJava2标准 的接口。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 RSemaphore semaphore = redisson.getSemaphore("semaphore" ); semaphore.acquire(); semaphore.acquireAsync(); semaphore.acquire(23 ); semaphore.tryAcquire(); semaphore.tryAcquireAsync(); semaphore.tryAcquire(23 , TimeUnit.SECONDS); semaphore.tryAcquireAsync(23 , TimeUnit.SECONDS); semaphore.release(10 ); semaphore.release(); semaphore.releaseAsync();
下面,我们使用Redisson演示分布式信号量的使用,我们在Controller增加方法:
1 2 3 4 5 @GetMapping("testSemaphore") public String testSemaphore () stockService.testSemaphore(); return "Hello Semaphore" ; }
在Service增加方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public void testSemaphore () RSemaphore semaphore = redissonClient.getSemaphore("semaphore" ); semaphore.trySetPermits(3 ); try { semaphore.acquire(); redisTemplate.opsForList().rightPush("log" , String.join("" , "线程【" , Thread.currentThread().getName(), "】获得了停车位" )); TimeUnit.SECONDS.sleep((long ) (Math.random() * 10 )); redisTemplate.opsForList().rightPush("log" , String.join("" , "线程【" , Thread.currentThread().getName(), "】把车开走了" )); semaphore.release(); } catch (InterruptedException e) { e.printStackTrace(); } }
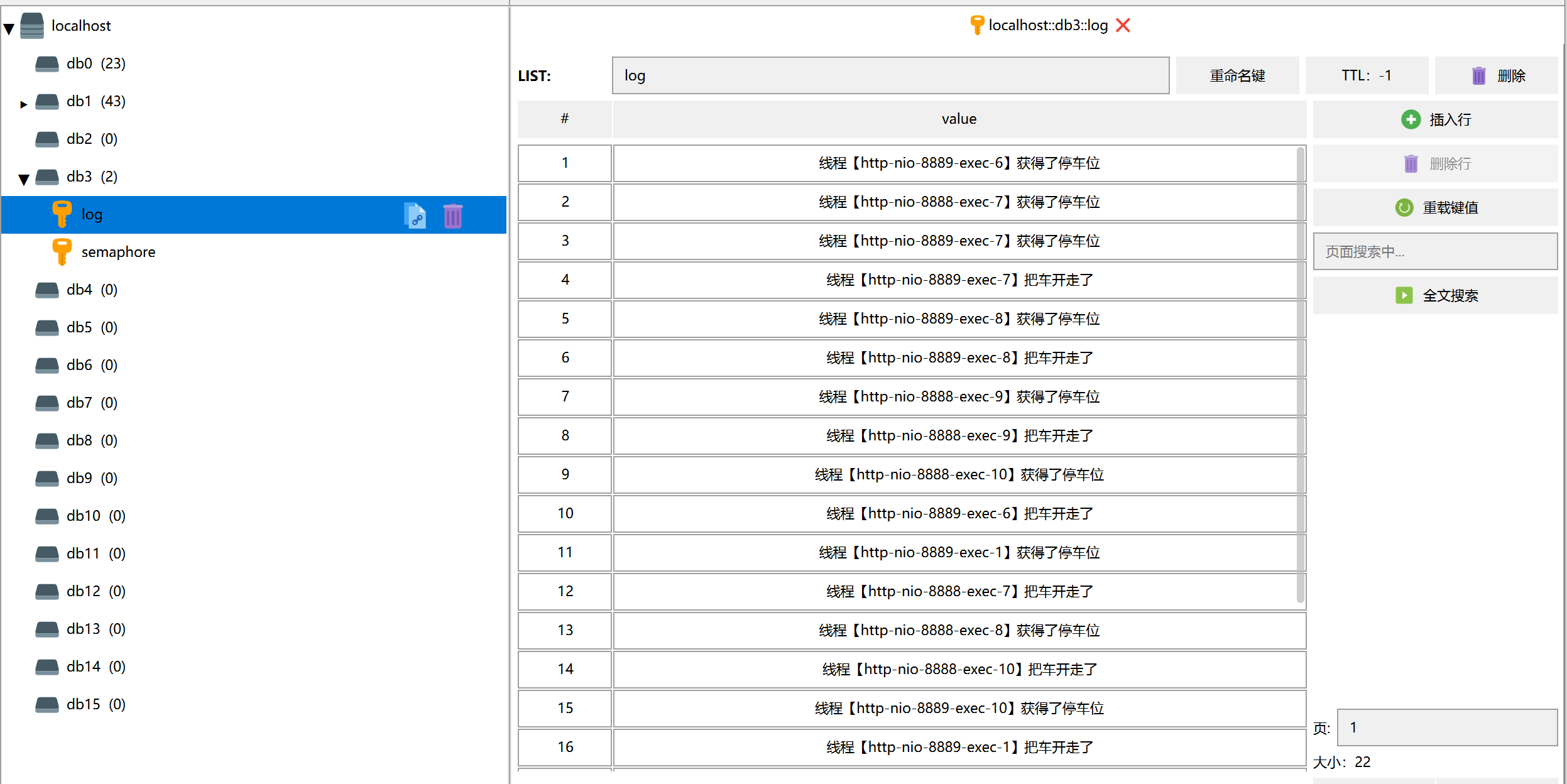
注意,这里我们是分布式集群部署,日志在两个控制台输出,不方便查看(顺序),因此,我们就日志存储到Redis的list中,日志不断往后追加,这样可直观的看到集群项目产生日志的顺序。添加完代码,我们可以在浏览器快速的发起10次请求进行测试。
通过Reids中的数据,我们可以发现,产生了两个键,一个是我们定义的信号量名称semaphore,一个是我们的日志log,通过日志可以发现,即使项目是集群部署,资源依旧被信号量安全的控制住,没有出现并发的逻辑问题。发起请求的过程中,我们可以观察到semaphore的值在0~3之间不断变动,代表着当前空闲的资源数量。
RRedisson之闭锁(CountDownLatch) 名词解释 闭锁,通俗来讲就是一个线程等待一组线程执行结束后,主线程才继续执行后续的逻辑,比如,在一个方法中,启用了10个线程来进行计算或其他逻辑处理,要等待这10个线程全部执行完毕,主线程才能继续往后执行,更或者是在不同的方法中调用,那么如何知道需要等待的线程是否都执行结束了呢,我们可以通过闭锁来实现,你可以把它简单理解为一个计数器,比如需要等待10个线程执行结束,那么计数器初始化为10,一个线程执行完毕就对数减一操作,直到数变为0,就是10个线程都执行结束了。
用一个例子来说明,一个班级有10个学生,他们需要乘坐一辆大巴去旅游,当10个学生全部上车之后,大巴才能关门并发车,于是,我们就需要监听,10个学生是否全部上车,我们让每个学生上车的时候都告诉司机一声,司机就可以算出剩余多少人没上车,知道剩余0人没上车,司机就可以关闭车门发车。下面我们使用JDK自带的闭锁java.util.concurrent.CountDownLatch来演示一下。
JDK的闭锁 首先,来看看不使用闭锁,会出现什么问题。
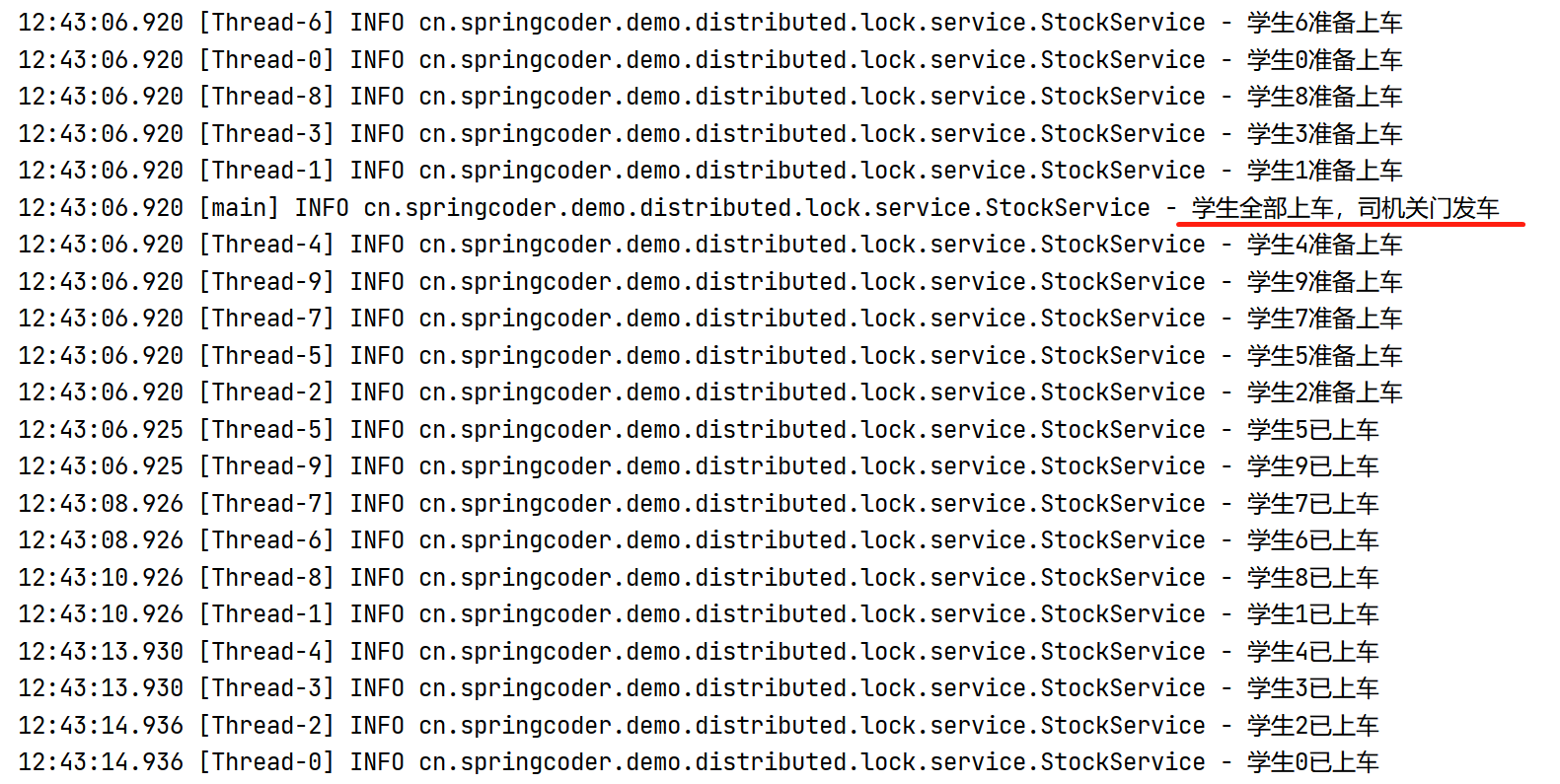
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public static void main (String[] args) for (int i = 0 ; i < 10 ; i++) { int finalI = i; new Thread(() -> { try { log.info("学生{}准备上车" , finalI); TimeUnit.SECONDS.sleep(new Random().nextInt(10 )); log.info("学生{}已上车" , finalI); } catch (InterruptedException e) { e.printStackTrace(); } }).start(); } log.info("学生全部上车,司机关门发车" ); }
通过日志可以发现,10个学生还在排队等待上车,司机就关闭了车门发车了,结果就是一个学生都没上车,下面我们改造下代码,使用JDK自带的闭锁来解决这个问题,当然,这个测试是在main方法中进行的,都是单机测试。我们改造后的代码为:
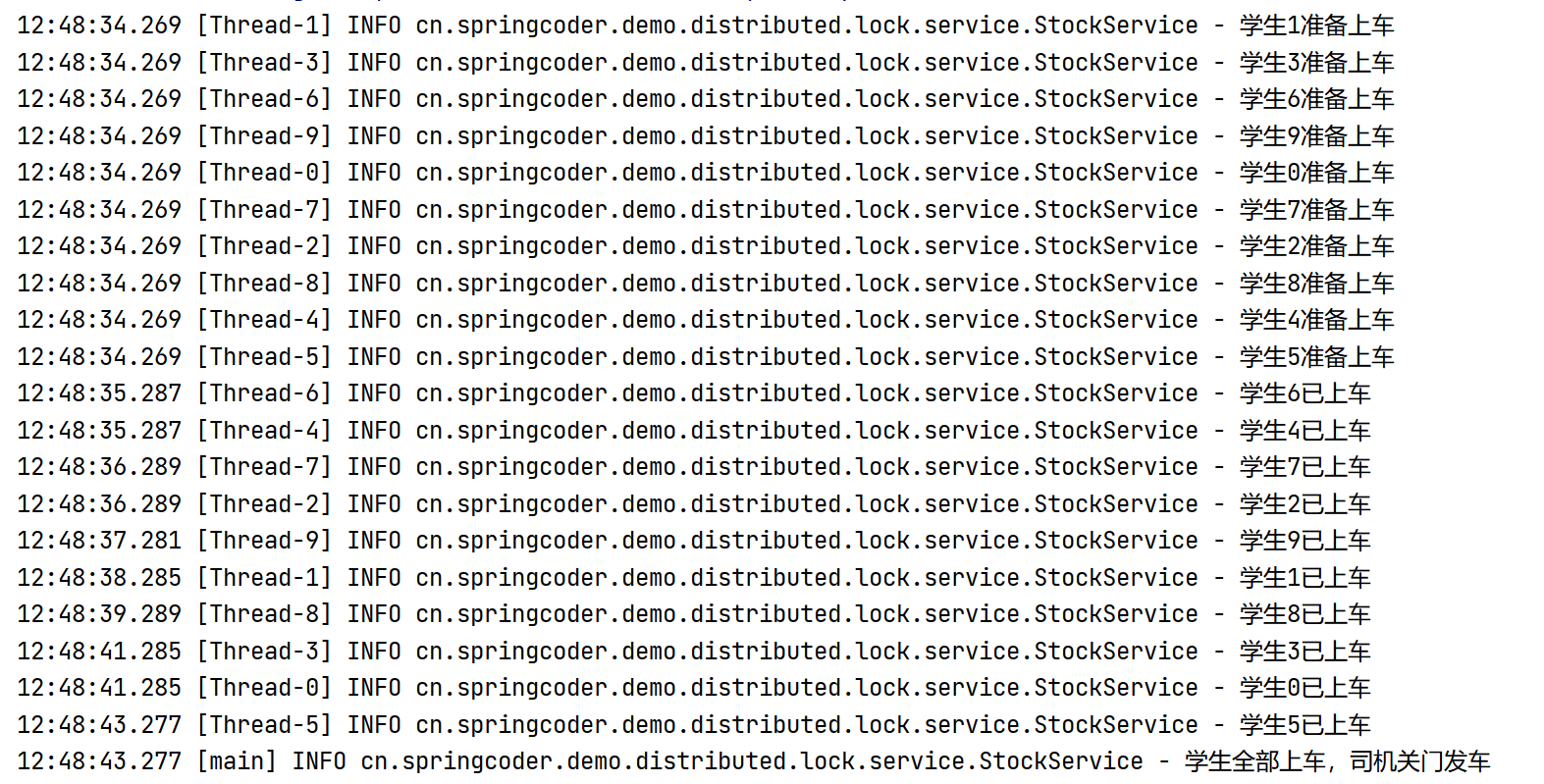
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public static void main (String[] args) throws InterruptedException CountDownLatch countDownLatch = new CountDownLatch(10 ); for (int i = 0 ; i < 10 ; i++) { int finalI = i; new Thread(() -> { try { log.info("学生{}准备上车" , finalI); TimeUnit.SECONDS.sleep(new Random().nextInt(10 )); countDownLatch.countDown(); log.info("学生{}已上车" , finalI); } catch (InterruptedException e) { e.printStackTrace(); } }).start(); } countDownLatch.await(); log.info("学生全部上车,司机关门发车" ); }
通过日志截图可以发现,司机(主线程)等待10个学生(10个线程)都上车之后,才进行关门和发车的动作。
同样的,JDK自带的这个计数器也有弊端,那就是当项目集群部署的时候,计数器就会失效,比如上面演示的代码,集群部署后(2个集群),原本是需要等待10个学生全部上车后关门发车的,会变成需要等待20个学生上车后才关门发车,因为每个集群都是判断需要等待10个,于是乎,我们可以通过Redisson的闭锁来解决分布式的问题。
Redisson的闭锁 基于Redisson的Redisson分布式闭锁(CountDownLatch )Java对象RCountDownLatch采用了与java.util.concurrent.CountDownLatch相似的接口和用法。
1 2 3 4 5 6 7 RCountDownLatch latch = redisson.getCountDownLatch("anyCountDownLatch" ); latch.trySetCount(1 ); latch.await(); RCountDownLatch latch = redisson.getCountDownLatch("anyCountDownLatch" ); latch.countDown();
可以看出来,Redisson的分布式可重入锁、公平锁、读写锁、信号量和闭锁的使用方式都大同小异,都与JDK的java.util.concurrent包下面的调用方法基本保持一致。